
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- vector
- 정석학술정보관
- 코딩
- Operating System
- 브루트포스
- Stack
- 백준
- DP
- coding
- 알고리즘
- 컴퓨터공학과
- 개발
- 오퍼레이팅시스템
- 구현
- cs
- 너비우선탐색
- bfs
- 자료구조
- 문제풀이
- 컴공과
- OS
- 그래프
- 코테
- 북리뷰
- Computer science
- 오에스
- 스택
- 컴공
- 정석
- c++
- Today
- Total
Little Jay
[CS] Byte Ordering(Big Endian, Little Endian)- Computer System 3rd Edition by Bryant 본문
[CS] Byte Ordering(Big Endian, Little Endian)- Computer System 3rd Edition by Bryant
Jay, Lee 2022. 2. 19. 14:56Byte Ordering
우리는 먼저 메모리에 bytes들이 어떻게 저장이 되는지 알아보자.
통상적으로 우리가 글을 읽을 때는 죄에서 우로 글을 읽는다.
반면, 아랍에서는 우에서 좌로 글을 읽는다. (하지만 아랍어 몰랐어도 풀 수 있는 문제들......)
이렇듯 국가별로 글을 읽는 방식이 다른데, 컴퓨터도 이와 마찬가지로 메모리 주소를 읽는 방식이 다르다.

컴퓨터 즉, HW에서 저장되는 데이터의 최소 단위는 1byte, 즉 8bit이다.
모든 기계적인 하드웨어에서 멀티-바이트의 객체들은 연속적인 바이트의 시퀸스(contiguous sequence
of bytes)로 저장이 된다.
예를들어 int x가 있고 32bit 컴퓨터에서 0x100번지부터 시작된다고 가정을 해보자.
그러면 이 x라는 변수는 4byte의 메모리 주소가 필요할 것이고, 이는 연속적으로 0x100, 0x101, 0x102, 0x103의 총 4byte의 메모리 지역을 할당받게 되는 것이다.
다른 예를 들어보면 char의 배열(C++에서는 string)이 있다고 하고, "HELLO!"라는 단어를 저장하고 싶다면,
메모리 주소에는 0x100, 0x101, 0x102, 0x103, 0x104, 0x105의 메모리 주소에 각각의 단어들이 저장될 것이다.

이 Byte Ordering에는 Little Endian, Big Endian 방식이 있다.
Bit Ordering
알다싶이 1byte는 8bit으로 이루어져있다.
HELLO!가 저장된 메모리 주소의 맨 앞인 0x100번지를 자세히 들여다 보면,
H의 아스키코드값인 0x48이 저장되어 있을 것이다.

이 bit는 뒤에 나올 Endian의 영향을 받지 않는다.
bit는 그냥 그대로 왼쪽에서부터 오른쪽으로 읽어주면 된다.
결국 메모리 영역에서 필요한 최소 단위는 Byte이지 Bit가 아니기 때문이다.
이 bit 영역에서 제일 왼쪽에 있는 bit을 최상위 비트(MSB: Most Significant Bit), 제일 오른쪽에 있는 bit을 최하위 비트(LSB: Least Significant Bit)라고 한다.
자세한 부분은 여기를 읽어보면 좋을 것 같다.
결과적으로 메모리에는 아래와 같이 저장이 된다.

Endian
Endian and endianness (or "byte-order") describe how computers organize the bytes that make up numbers.
엔디언(endian, endianness) 또는 바이트 순서는 숫자를 구성하는 바이트를 컴퓨터가 정렬하는 방법입니다.
출처: MDN Web Docs, https://developer.mozilla.org/ko/docs/Glossary/Endianness
엔디언은 크게는 빅 엔디안(Big Endian), 리틀 엔디안(Little Endian)의 두가지로 나눌 수 있고, 더 세분화 할 수 있다.
사실상 엔디언이 적용되는 영역을은 2byte 이상일 때 이다. (2byte 이상부터 저장되는 순서가 endian을 따르기 때문)
- 빅 엔디안
- 리틀 엔디안
- 바이 엔디안(빅 엔디언과 리틀 엔디언 중 하나를 선택할 수 있도록 설계되어 있는 아키텍쳐)
- 미들 엔디안(종종 한 방향으로 순서가 정해져 있는 게 아니라, 이를테면 32비트 정수가 2바이트 단위로는 빅 엔디언이고 그 안에서 1바이트 단위로는 리틀 엔디언인 경우)
빅 엔디안(Big Endian)
int x 에 0x01234567을 저장하고 메모리 주소가 0x100번지부터 시작한다고 해보자.
이렇게 우리가 일반적으로 생각하듯이 왼쪽에서 오른쪽으로 저장되는 방식이 Big Endian 방식이다.
즉, 상위 바이트의 값이 메모리에 우선적으로 저장이 되는 것이다.

리틀 엔디안(Little Endian)
반면 앞서 정의한 x가 리틀 엔디안 방식을 따른다고 하자.
이는 빅 엔디안과 반대로 오른쪽에서 왼쪽으로 저장되는 방식이다.
즉, 하위 바이트 값이 메모리에 우선적으로 저장이 되는 것이다.

컴파일러나 cpu가 이를 읽을때는 0x67452301로 읽지 않고, 처음에 우리가 의도한대로 0x01234567로 읽는다.
당연하지만 이는 저장 방식의 차이 이고, cpu는 이를 정상적으로 읽는다.

Little Endian vs. Big Endian
이 두 방식의 차이는 명확하고 당연하게도 사용하는 곳이 명백히 다르다.
| Big Endian | Little Endian |
| IBM's 370 mainframes | Intel x86 |
| RISC-based computers | AMD |
| Motorola microprocessors | DEC Alphas |
| TCP/IP | Qualcom Hexagon |
사용처가 명확히 다른 만큼 항상 이를 인지하고 사용해야 한다.
Little Endian은 Intel 혹은 AMD계열 cpu에서 사용된다. 일반적인 컴퓨터에서 사용된다.
Little Endian의 장점들에 대해 소개한다면,
가산기에서의 편리한 활용
cpu는 수많은 레지스터와 가산기들로 이루어져있다. Little Endian은 가산기를 활용할 때 carry bits를 처리하는데 상당한 도움을 준다. 리틀 엔디안은 두 숫자의 가산 연산을 할 때 LSB에 있는 숫자를 계산하고 carry bit를 다음 가산기에 추가를 해주는 식으로 동작한다. 아래의 그림을 보면 carry bit가 발생하면 FA(Full Adder)가 carry bit를 넘겨주는 것을 볼 수 있다. 결론적으로 우리가 덧셈을 할 때 아래자리부터 계산을 하는데 이와 똑같이 동작하기에 리틀 엔디안을 사용했을때 연산 속도가 Big Endian보다 빠르다.
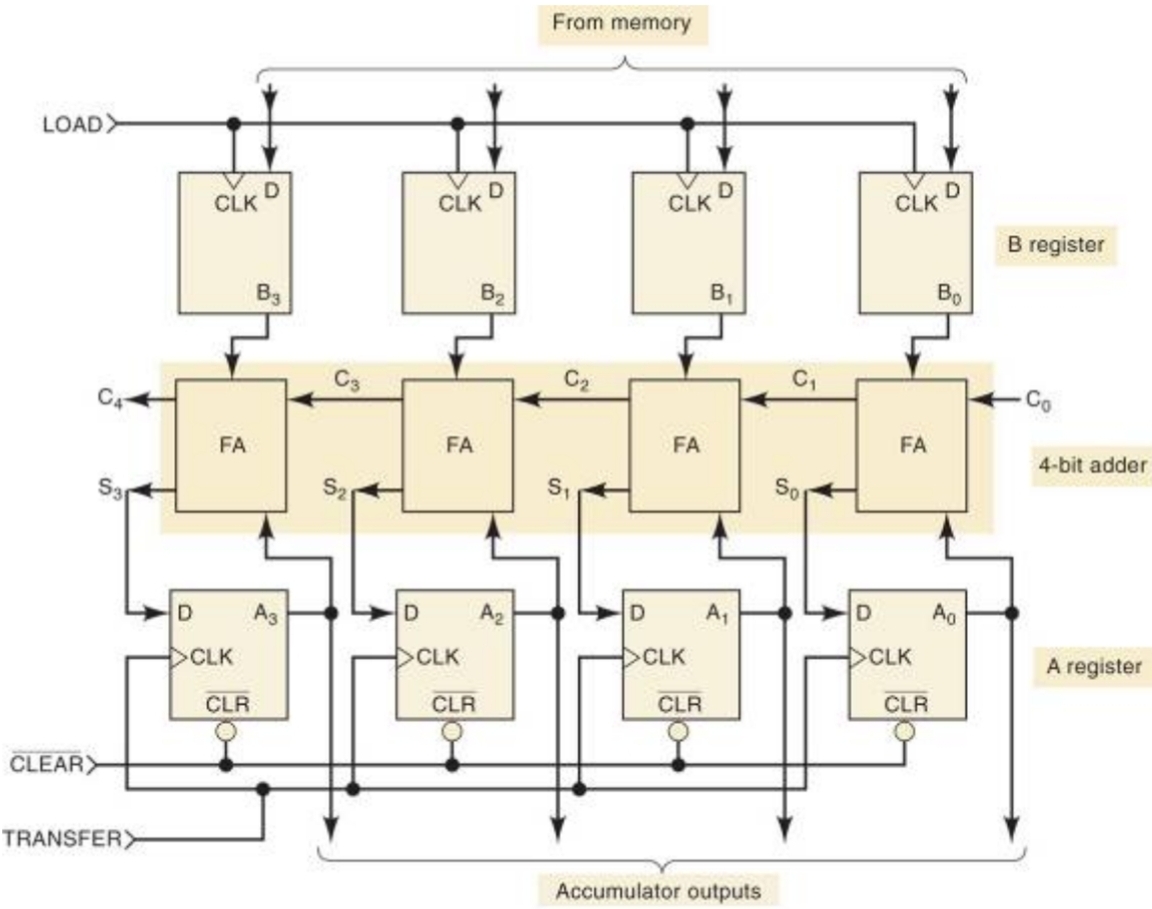
빠른 형변환
저장된 값의 하위 바이트들만 사용할 때 별도의 계산이 필요 없다는 것이다.
예를 들어 0x1A는 리틀 엔디안 방식으로 표현하면 1A 00 00 00 이 되는데 이 표현에서 앞의 두 바이트 또는 한 바이트만 떼어 내면 하위 16 비트 또는 8 비트를 바로 얻을 수 있다. 반면 32bit 빅 엔디안 방식 환경에서는 하위 16 비트나 8 비트 값을 얻기 위해서는 변수 주소에 2바이트 또는 3바이트를 더해야 하기 때문에 계산이 또 들어간다. 타입을 읽거나 형변환을 진행할 때 빅 엔디안 보다 빠른 이유가 여기에 있다.
Big Endian은 대부분 대형 UNIX 서버에 사용되는 RISC 계열의 CPU에서 사용된다.
이에 대한 장점들을 간단하게 소개하자면
수 비교
빅 엔디안에서는 숫자 비교를 MSB부터 차례로 진행하기 때문에 숫자를 비교할때 큰 이점이 있다. 네트워크에서는 속도가 우선시 되는데 네트워크 프로그래밍을 할 때 빅 엔디안을 사용하는 이유가 여기에 있다.
쉬운 디버깅
숫자가 그래도 메모리에 저장된다는것은 인간으로 하여금 디버깅하는데 확실히 편하다. 리틀 엔디안으로 저장된다면 이를 자료형의 사이즈만큼 뒤로 간 후 거기서부터 읽어야하는데, 빅 엔디안은 그럴 필요가 없이 왼쪽에서부터 쭉 읽으면 된기에 디버깅할 시 메모리 값을 보기가 편하다는 장점이 있다.
Network Byte Order
네트워크 데이터 통신에서는 네트워크 바이트 순서(Network Byte Order)를 따르도록 데이터의 바이트 순서를 변경해야 한다. (TCP/IP, XNS, SNA 규약은 16비트와 32비트 정수에서 Big Endian 방식을 사용함)
따라서 시스템이 Little Endian 방식을 사용할 경우 네트워크를 통해 데이터를 전송하기 전에 Big Endian 방식으로 데이터를 변경해서 보내야만 하고 받을 때는 Little-Endian 시스템은 전송되어 오는 데이터를 역순으로 조합해야 한다.
이를 지원해주는 함수들이 있는데, 아래와 같다. 아래의 그림을 보면 저 함수의 직관적인 의미를 알 수 있다.
unsigned short htons (Host to Network Short) - short 메모리 값을 호스트 바이트 순서에서 네트워크 바이트 순서로
unsigned long htonl (Host to Network Long) - long 메모리 값을 호스트 바이트 순서에서 네트워크 바이트 순서로
unsigned short ntohs (Network to Host Short) - short 메모리 값을 네트워크 바이트 순서에서 호스트 바이트 순서로
unsigned long ntohl (Network to Host Long) - long 메모리 값을 네트워크 바이트 순서에서 호스트 바이트 순서로

Reference
https://ko.wikipedia.org/wiki/%EC%97%94%EB%94%94%EC%96%B8
https://jhnyang.tistory.com/172
http://www.ktword.co.kr/test/view/view.php?m_temp1=2354
https://www.geeksforgeeks.org/little-and-big-endian-mystery/
https://developer.ibm.com/articles/au-endianc/#end
https://developer.mozilla.org/ko/docs/Glossary/Endianness
https://koromoon.blogspot.com/2020/09/byte-ordering-big-endian-little-endian.html
https://uynguyen.github.io/2018/04/30/Big-Endian-vs-Little-Endian/
https://genesis8.tistory.com/37
Computer Systems A Programmer’s Perspective Third edition, Randal E. Bryant • David R. O’Hallaron, Pearson, 2016
Digital Systems Principles and Application, 12th ed, Neal S. Widmer, Gregory L. Moss, Ronald J. Tocci, Pearson, 2018



