
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- Operating System
- Stack
- c++
- DP
- 문제풀이
- 구현
- Computer science
- cs
- 그래프
- 백준
- 컴공과
- vector
- 알고리즘
- 코테
- 너비우선탐색
- bfs
- 개발
- 오퍼레이팅시스템
- 스택
- 브루트포스
- 컴퓨터공학과
- 컴공
- 코딩
- 북리뷰
- coding
- 정석학술정보관
- 자료구조
- 오에스
- 정석
- OS
- Today
- Total
Little Jay
[CS] Array & Pointers 배열과 포인터 - Computer System 3rd Edition by Bryant 본문
[CS] Array & Pointers 배열과 포인터 - Computer System 3rd Edition by Bryant
Jay, Lee 2022. 3. 2. 18:41배열을 경험해보지 못한 개발자는 없을 것이다.
배열은 컴퓨터 내에서 연속적인 메모리 공간을 사용할 수 있는 좋은 자료구조이다.
T arr[n] 이라는 배열이 있으면, 이는 T라는 자료형에 n길이 만큼 data가 있다는 소리이다.
이때 이 size는 n * sizeof(T) 만큼의 메모리 공간에 연속적으로(Continously) 존재하게 된다.
그리고 arr이라는 이름은 배열의 시작을 가르키는 포인터처럼 사용할 수 있다.
char buf[256]; 이라고 선언 후, char *p = buf; 라는 포인터변수를 선언하면 단순히 이 포인터를 가지고서 배열을 다룰 수 있는 것이다. 보통 리눅스 계열에서 포인터는 일반적으로 8byte를 가리키며, n length의 포인터 배열을 선언하게 되면 n * 8의 사이즈의 배열이 만들어지게 된다.
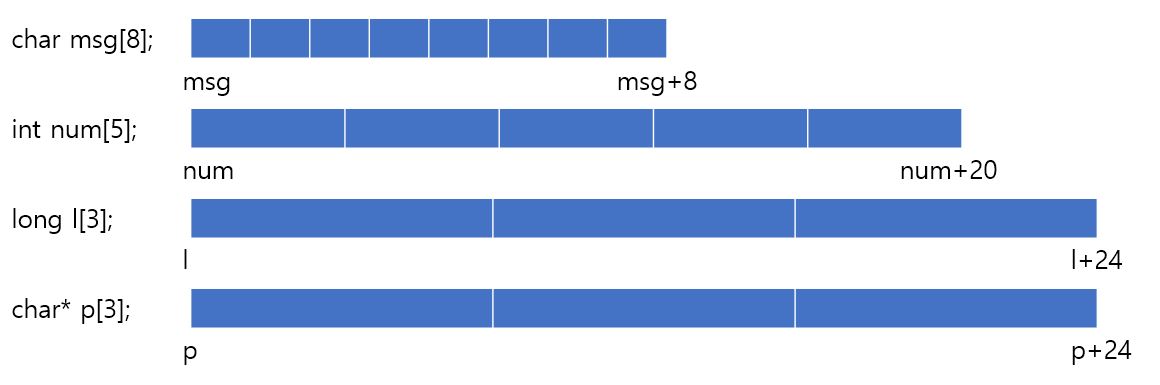

또한 흔히 사용되는 배열은 2차원 배열일 것이다.
행렬식 계산을 할때나, 그래프 탐색 문제들(dfs, bfs 등)에서 이차원 배열을 정말 많이 사용된다.
우리가 2차원이라고 해서 실제 이차원 배열은 메모리상에 이차원으로 존재하지 않는다.
즉, 2차원 배열도 하나의 긴 일차원 배열의 형태로 메모리에 저장이 될 뿐 이차원으로 저장되는 것이 아니다.
우리가 이해하기에 편하게 이차원으로 그리고, 생각하기 편하기 때문에 이차원배열로 그리는 것이지, 실제 메모리에는
연속적인 배열로 존재하는 것이다. 예를들어 아래와 같이 T arr[r][c]라는 배열을 선언했다면, 아래와 같이 만들어진다.
이러한 정렬된 방식을 row-major ordering이라고 부른다. 이 배열의 사이즈는 아래와 같다.

int *get_arr(int idx) {
return arr[idx];
}
int arr[4][5] = {
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5}
};위와 같은 코드가 있다고 하자. 결국 이 배열이라는 것은 하나의 긴 메모리 주소상에 존재하는 것이므로 어셈블리어를 분석하면 아래와 같은 instruction을 수행하게 된다.
// %rdi = idx
leaq (%rdi, %rdi, 4), %rax // 5 * idx
leaq arr(,%rax,4), %rax // arr + (20 * idx)이 assembly 코드는 arr + 4*(idx + 4*idx), 즉 arr + 20*idx를 수행하고 있는 것이다.
이는 이차원 배열의 subarray 즉 한개의 row를 꺼내오는 코드의 역할을 수행한다.
int get_digit(int idx, int digit) {
return arr[idx][digit];
}
int arr[4][5] = {
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5},
{1, 2, 3, 4, 5}
};반대로 이번에는 배열의 특정 원소를 꺼내오고 싶다면 위와 같은 코드를 작성할 수 있다.
이 역시 assembly code로 변형을 해보자면 아래와 같을 것이다.
leaq (%rdi, %rdi, 4), %rax // 5*idx
addl %rax, %rsi // 5*idx + digit
movl arr(,%rsi, 4), %eax // *(arr + 4*(5*idx+digit))Multi-Level Array
일반적으로 multi-level array라고 하면 포인터 배열에 다른 배열의 주소값이 담겨있는 것을 의미한다.
int inha[3] = {1, 2, 3};
int harvard[3] = {4, 5, 6};
int hawaii[3] = {7, 8, 9};
int *univ[3] = {inha, harvard, hawaii};각각의 배열 명은 array의 시작 주소를 의미하므로 이렇게 만들 수 있다.
이러면 메모리상에서는 아래와 같이 저장이 된다.
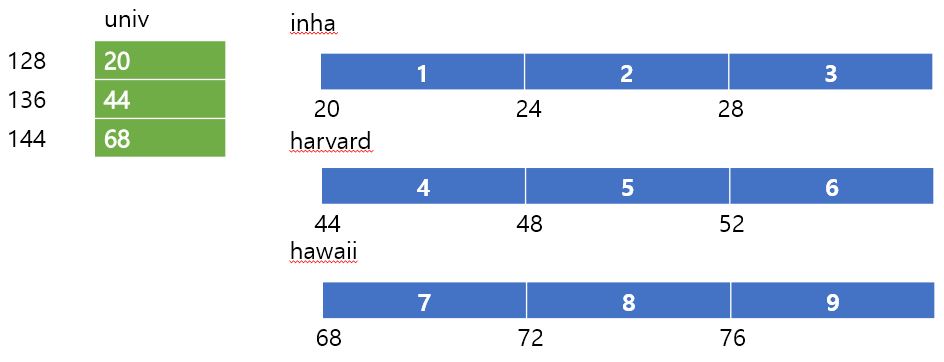
각각의 배열 자체는 연속적이다. 물론 당연하게도 univ라는 포인터 배열의 경우에도 적용이 된다.
포인터 배열의 크기는 8byte로, 각 대학은 int 형이기에 4byte로 저장이 된다.
Derived Types
우리가 대표적으로 알고 있는 char, short, int, float, double, long 등은 Basic Data Types이다.
이들을 활용한 Data Type들을 Derived Type이라고 부른다.
Derived가 '파생된'이라는 의미이기 때문에 충분히 유츄가 가능할 것이다.
이 데이터 타입에는 Pointer Type, Array Type, Function Type, Structure Type, Union Type이 존재한다.
Derived Type 외에도 Enumerated Type이 존재하는데 이는 단순히 enum 열거체이므로 본 포스팅에서는 생략하겠다.
포인터는 아스테리크 기호로 사용한다. char *foo라고 하면 foo is pointer to char. 이렇게 해석할 수 있다.
배열은 알다싶이 대괄호를 붙인다. int foo[5]; 라고 하면 foo is array if 5 ints. 이렇게 해석할 수 있다.
함수는 소괄호를 사용한다. long foo()라고 하면 foo is a function returning a long. 이렇게 해석이 가능한다.
문제점은 이러한 type들이 혼용이 되어서 사용될 때 이다.
이렇게 되면 순서관계를 파악하기 어려운데, 이럴때는 C에서 규약한 Operator 우선 순위를 참조해야한다.
아래 새 개에 한해서는 소괄호와 대괄호의 우선순위가 제일 놓고, 그 다음이 별표시와 앰퍼센드 표시이다.
이 데이터 타입을 이해한다면 우리는 배열의 크기를 쉽게 알 수 있다.
int a1[3]은 12byte인 것이 바로 계산이 되고, int *a2[3]은 pointer이기 때문에 24byte로 계산이 된다.
반면 int (*a3)[3]은 8byte이다. 왜 그럴까?
이를 Operator 우선순위에 맞게 해석을 한다면 a3는 pointer이다. 그렇기 때문에 a3 자체는 int 3개짜리 배열을 가리키고 있는 하나짜리 포인터 배열이 되는 것이다.
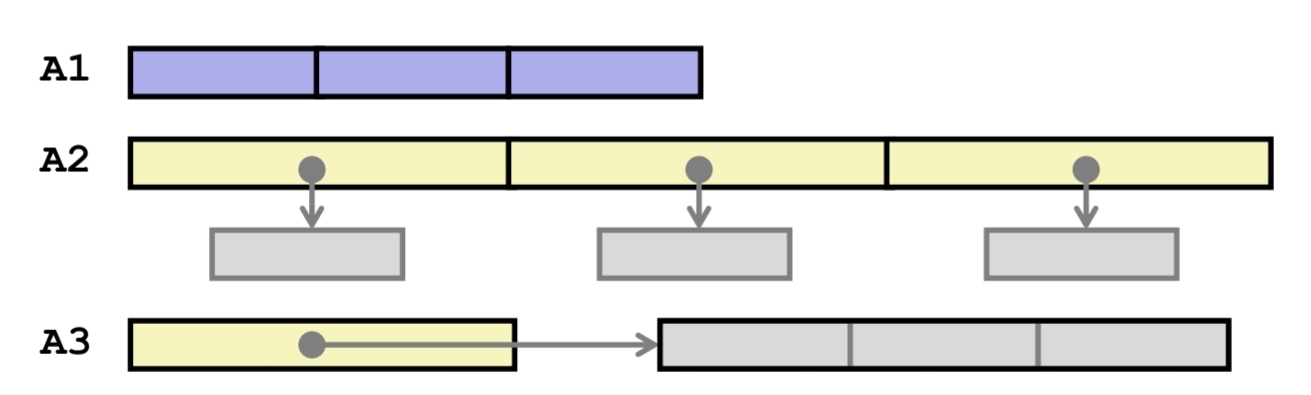
이런식으로 생각을 해본다면, 다른 예시에서도 쉽게 배열의 사이즈를 구할 수 있을 것이다.
int *a1[3][5]는 120byte, int (*a2)[3][5]는 8byte, int (*a3[3])[5]는 24byte가 된다는 것을 알 수 있다.
이렇듯 배열의 크기를 미리 안다면 임베디드 시스템이라든지 메모리가 매우 작은 영역에서 도움이 되지 않을까 싶다.
Reference
Randal E. Bryant, & David R. O’Hallaron. (2016). Computer Systems A Programmer’s Perspective Third edition. Carnegie Mellon University: Pearson.



