
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Computer science
- Stack
- c++
- 너비우선탐색
- bfs
- 정석
- OS
- DP
- 문제풀이
- 코딩
- 스택
- 오퍼레이팅시스템
- Operating System
- cs
- 자료구조
- 그래프
- coding
- 컴공
- 개발
- 구현
- 컴퓨터공학과
- 컴공과
- 코테
- 오에스
- 백준
- 브루트포스
- vector
- 정석학술정보관
- 북리뷰
- 알고리즘
- Today
- Total
Little Jay
[OS] Operating System Overview II (Evolution through History) 본문
[OS] Operating System Overview II (Evolution through History)
Jay, Lee 2022. 7. 19. 16:11Evolution of OS
개괄적으로 정리해보자면 1940년대 중반에서는 컴퓨터라고 하는 것은 국가적인 재산이었다. 에니악의 크기만 봐도 개인이 소유할 수 없는 국가적인 재산이었다. 하지만 이용율은 매우 낮았던 시기이다. 그렇기 때문에 점차 이용률과 Utilization을 높이는 것이 목표가 되면서 진화했다. 그러나 현대에 와서는 HW보다는 인간의 몸값이 더 비싼 수준이 되었다. 따라서 평균대기시간과 turn-around time을 줄이는 것이 목표가 되었고 인적 자원을 idle하지 않게 interactive한 시스템으로 진화해왔다. 결과적으로 HW와 OS는 서로 영향을 주면서 발전해왔다고 할 수 있다.
Serial Processing
이 시대는 1940년대 중반수터 1950년대 중반까지의 시대이다. 이 당시의 컴퓨터는 진공과으로 만들어졌으며, 펀치 카드와 tape등을 이용해서 컴퓨팅을 하였다. 에니악이 대표적인 예시이다. 에니악이 그 당시 달러로 $500,000달러라고 하는데, 물가 상승률을 고려한다면 2019년에는 약 $7,196,000 달러라고 한다. 따라서 이는 국가적으로 활용이 되었다. 이 시기에는 OS라는 개념이 존재하지 않았고 사람이 직접 Operator로서 일했다. 사람들이 일련의 작업들을 수행하기 위해서 펀치카드를 넣고 돌리면서 일했고, 덕분에 모든 program들은 Sequential하게 동작했다. 이 당시의 소스코드들은 펀치카드를 활용한 Assembly언어나 High Level Language였다.
당연하게도 이제는 이러한 방식을 채택하여 사용하고 있지 않는다. 문제점을 꼽자면 3가지 정도로 말할 수 있는데, 먼저 컴퓨터라는 값비싼 자원을 효율적으로 사용하지 못했다. 그 당시에는 획기적이었을지 모르겠지만, 병렬처리도 안되고 Sequential하게 코드가 돌아가고 속도도 지금보다는 매우 느렸다. 여기에 뒤따라 오는 문제점들은 먼저 Scheduling Time의 문제점이었다. 이 당대에는 사람들이 컴퓨터를 사용하기 위해 사용시간을 예약해야했다. 전공강의실에 시간표에 따라 자리를 비켜주듯이 컴퓨터를 사용하는 시간을 예약해서 정해진 시간만 사용할 수 있었다. 따라서 정해진 사용 시간을 넘겼을 때는 다른 사람에게 피해가 가고, 시간을 꽉 채우지 못했다면 컴퓨터 입장에서는 idle한 시간이 생기는 것이므로 utilization 측면에서 좋지 않았다. 여기에 뒤따라 오는 것이 높은 Setup Time의 문제였다. 서로 다른 High Level Language를 사용했을 때 컴파일러를 load, unload하는 시간이 뒤따랐다. 예를 들어 세 사람이 연속적으로 컴퓨터를 사용한다고 했을 때 앞사람은 Assembly를 뒷사람은 Fortran을, 마지막 사람은 다른 High Level Language를 사용한다고 하자. 그렇게 되면 각 언어에 맞는 Compiler를 컴퓨터에 Load, Unload해야하는데 이 시간이 어느정도 걸린다고 했다. Serial하게 수행되는 것이기 때문에 이를 load, unload하는 시간을 고려하지 못한다면 개인에게 주어진 Scheduling Time을 오버하기도 하고, 그렇다고 너무 시간을 넉넉히 잡으면 Utilization이 줄어드는 상황들이 발생했다.
Simple Batch System
따라서 비슷한 job들끼리 묶어서 setup time을 줄이고자 하는 목적으로 Simple Batch System이 등장했다. 예를 들어 Fortran Compiler가 두번 연속으로 들어온다면 Compiler를 두번 load, unload하는 것이 아니라 한번씩만 해도 Setup Time은 1/2로 줄어들게된다. 또한 이를 통해 Automatic job Scheduling이 가능해지면서 Human Operator의 개입을 최소화하고자 했다. 따라서 이때부터 OS가 상주해야하는 것의 필요성을 느꼈고, 이때 등장한 첫 번째 OS가 바로 Monitor이다. IBM 701에서부터 사용했다고 하며, Monitor는 항상 Main Memory에 상주하여 다른 Device들을 관리하기 시작했다. 또한 이때 등장한 것이 Job Control Language(JCL)인데 사람들이 특별한 카드를 넣어 일괄 처리 작업을 수행하거나 하부 시스템을 시작하는 방법을 시스템에 지시한다. (위키피디아 참조) 자세한 것은 Link를 참조하는 것이 좋겠다. 어째뜬 이는 job의 제어 흐름을 위해서 등장했다. 이 당시에도 Monitor는 User가 사용가능한 영역과는 분리되어 하나의 메모리 안에 존재했다.

Simple Batch System은 개발하고 나서 선대 공학자들께서는 여전히 부족한 점이 보이셨다. 첫 번째로 Monitor의 Memory Protection이 필요하다는것. User 코드가 Monitor의 메모리 주소 이상으로 넘어가면 당연히 문제가 생기기 때문에 이를 철저하게 분리시킬 수 있는 기술이 필요했다. 또한 Monitor에 System Timer를 달아준다면 시스템으로 하여금 하나의 job이 독점적으로 사용이 되는 것을 막을 수 있지 않을까라는 좋은 지적점이 등장했다. 또한 Privileged Instruction을 Monitor 내에서만 사용함으로서 OS가 독점적인 명렬어를 명령어의 필요성이 대두되었다. 예를 들어 I/O 명령어를 User가 사용하는 것이 아닌 Kernel에서만 사용하도록 했다. 그렇기 때문에 I/O Device Controller의 필요성도 자연스럽게 등장했다. CPU의 Utilization을 높이기 위해 별도의 I/O Device Controller를 두어 CPU와 I/O Device를 동시에 작업이 가능해졌다. 마지막으로 CPU의 Interrupt와 Asynchronous I/O가 Overlapping되는 것을 지원했다. I/O가 CPU에 종속적인 Synchronous I/O일때는 Wait이 걸린다. 예를 들어 scanf같은 것이 있다. 그러나 Asynchronous I/O는 CPU와 종속성이 없고 Parallel하게 동작하게 된다. 더 이상 기다릴 필요가 없이 Overlapping되면서 동작할 수 있게 되는 것이다. 이러한 특성들을 반영하면서 Simple Batch System은 진화를 거듭해왔다.
그러나 Simple Batch System도 여전히 문제점을 지니고 있었다. 아직 이 시대는 펀치카드로 작업을 했었기 때문에 Card Reader의 속도가 현저하게 떨어졌었다. Automatic Job Sequencing에도 불구하고 I/O Device는 여전히 Processor에 비해 느렸다. 또한 Synchronous I/O와 CPU는 여전히 Overlap될 수 없기 때문에 CPU가 종종 Idle해 Utilization이 떨어지기도 했다.
Multiprogrammed Batch System
따라서 이제는 CPU Utilization을 높일 수 있는 방법을 찾아야했다. 우리가 지금까지 했던 방식은 CPU에 하나의 Program만 올라가는 Uni-Programming이었다. 그러나 이제는 여러개의 active한 job들을 Main Memory에 올려 CPU가 Idle한 것을 막고 Utilization을 올리고자 했다. 따라서 이제 Multi-Programming의 시대가 열리기 시작했다. 그러나 헷갈리지 말아햐 하는 것은 Multi Processing과 Multi Programming의 차이이다. Multi Processing은 CPU에서 작업이 병렬적으로 실행되기에 Uni Programming에서도 가능하지만 Multi Programming은 Job들이 Memory에 여러개가 올라가있는 것이다. Memory에 올라갈 수 있는 Program은 적절한 CPU의 Scheduling 알고리즘에 의해 선택된다.

아래의 그림은 Program을 실행하다가 I/O가 발생해서 Wait을 하는 것을 Uni-Programming에서 Multi-Programming으로 넘어갈 때 CPU의 효율이 좋아지는 것을 보여준다. the Degree of Multiprogramming이라는 용어가 있는데 이는 메모리에 올라갈 수 있는 Program의 정도이다. 이 Degree가 1일때는 Wait이 상당히 길지만 Degree가 점점 높아질수록 Wait하는 시간이 점점 줄어들게 된다. 단순히 Wait이 발생하면 Processor는 Job을 Switch하여 다른 일을 수행하면 되기 때문이다. 따라서 the Degree of Multiprogramming과 CPU Utilization이 비례관계에 있다는 것은 자명한 사실이다.
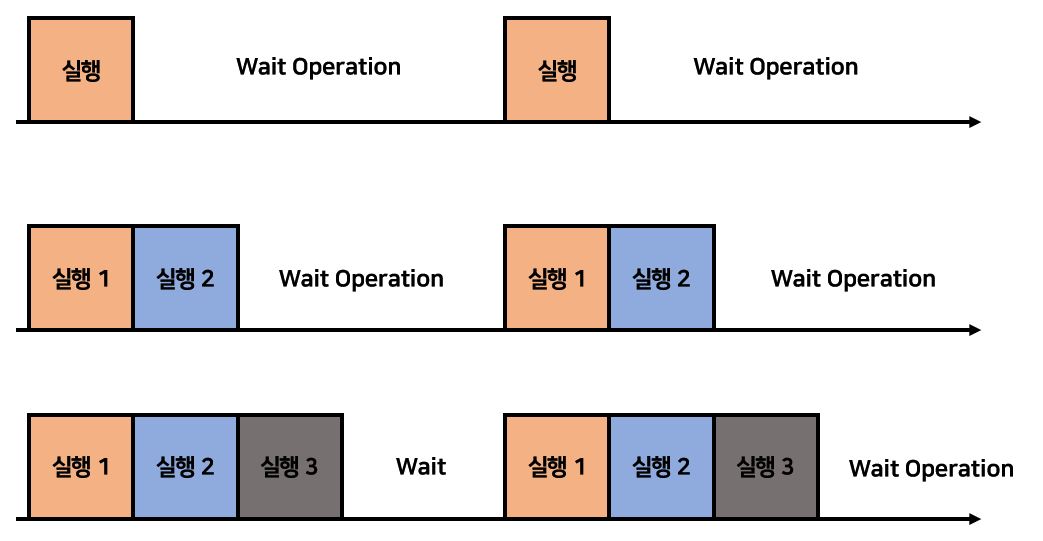
그러나 당연히 이 방식도 완전하지는 않았다. 이제는 Relocation에 대한 문제가 발생했다. Uni-Programming에서는 Program이 하나만 올라갈 수 있었기 때문에 Program의 시작주소를 정적으로 알 수 있었다. 그러나 Multi-Programming에서는 Program들의 시작 위치를 미리 알 수가 없었다. 이는 오직 OS가 알고있는 것이며, Kernel 모드에서 OS가 관리해주는 영역이 되어버렸기 때문이다. 또한 Program이 3개 들어가 있는 상황에서 첫 번째 프로그램이 끝나면 네 번째 Program4를 Memory에 반입하고, Program1과 Swap해야 할것이다. 그러나 만약 Program1보다 Program4가 더 크다면? 또한 Program4가 Program1보다 현저히 작아 메모리에 빈 공간이 생겨버리면? 들의 문제점들이 생겨나기 시작했다. 동적으로 계속 Program들을 swap해야하는데 이 문제를 어떻게 해결할 것인지에 대한 문제와 Memory Protection의 문제가 대두되었다. Simple Batch System에서는 Program과 OS의 메모리 문제였다면 이번에는 Program들간의 Memory 충돌이 일어나는 경우이다.
따라서 이러한 문제를 해결하기 위해 Memory Management Unit(MMU)라는 HW가 등장하게 되었다. Relocation으로 인해 Program들의 Memory 주소가 동적으로 변화하기 시작했기 때문에 이를 세분화 할 필요가 있었고, 이는 Running Time에 OS가 결정하는 것이기 떄문에 Runtime Address와 실제 Physical Address가 달라질 수 있었다. 따라서 이를 적절히 변환시켜주고 배치시켜주는 MMU의 등장이 이루어졌다. MMU는 Vitrual Address와 Memory 파트에서도 다룰 것인데, 짧게 설명하자면 우리가 Program을 짤때는 실제 Memory의 주소를 고려하지 못한다. Device마다 Memory공간도 다르고, 메모리 주소도 동적으로 계속해서 변한다. 따라서 우리는 항상 상대주소로 Programming을 한다. MMU는 이를 적절한 Base Register에 있는 주소와 더하고, Bound(limit) Register와 비교해서 이를 넘기는지 확인한다. 넘지 않으면 Memory에 올라갈 수 있고, 없다면 Exception이 발생하게 되는 것이다. 결론적으로 주소 변환을 해주는 HW라고 생각하면 되겠다. 사실 이를 SW적으로 구현을 할 수 있지만, HW를 사용하는 것이 더 좋다. MMU가 SW라면 이도 결국 Program이기에 메모리에 올라가있어야하고, SW라면 CPU를 거쳐서 결과를 return해주는데 HW는 그럴 필요가 없기 때문이다. 또한 여러 이유가 있지만 자세한 것은 컴퓨터 구조론이나 뒤의 Memory, Virtual Memory를 정리하면서 다루겠다.

Time Sharing Systems
이제는 직접도의 향상으로 인한 HW의 비용이 감소해지고, Human Resource에 대한 Cost가 증가했다. 따라서 이제는 사람들을 더 효율적으로 사용하고, Interactive한 작업을 다룰 수 있어야했다. 그리고 Processor의 Time이 Multiple User에게 Sharing되기 시작했다. 그렇기 때문에 Time Sharing System의 목표는 Response Time을 Minimize하는 것이 목표가 되었다. Multiprogramming은 CPU Utilization을 Maximize하는 것이 목표임을 잊지 말자.
이제는 Interactive Timesharing으로 인해 모든 User가 Terminal을 가지고 있고, 사람들로 하여금 하나의 Device에 Multiple User들이 접속할 수 있었다. 그래서 User들은 Switch가 자주 일어나게 되기 때문에 각 작업마다 time slice가 부여되었다. 이때부터 preemption(선점)을 통해 time out되면 CPU는 다음 Slice로 묻지도 따지지도 않고 이동하게 되었다.
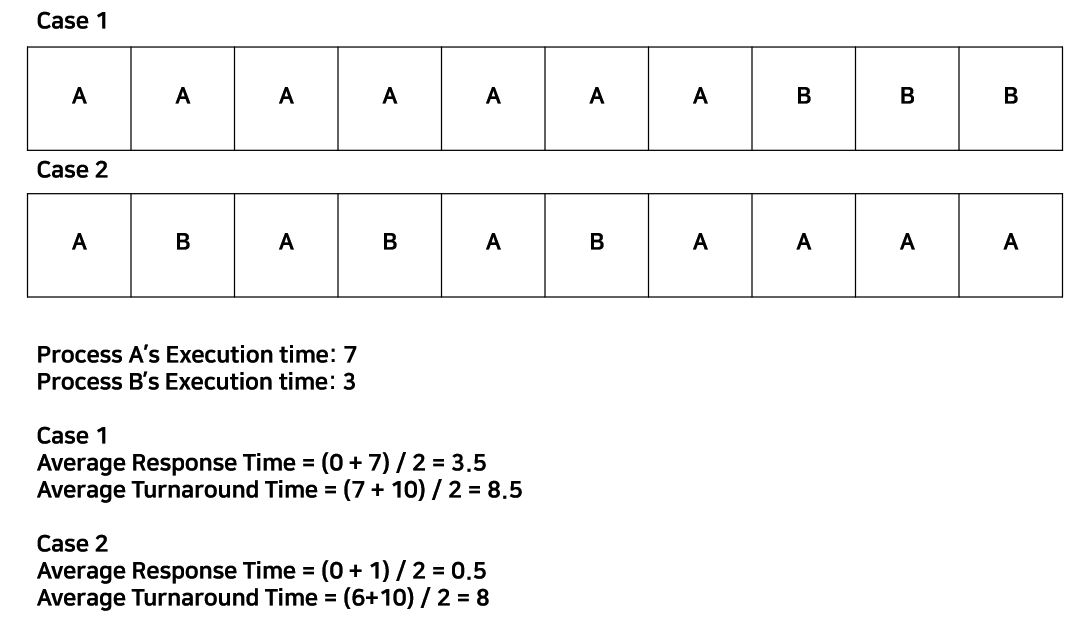
위의 그림을 보자. Case 1은 preemption 기법을 사용하지 않은 것이고, Case 2는 preemption기법을 사용한 것이다. Response Time은 응답시간이기 떄문에 각 Process의 시작 시간의 sum / process의 수이고, Turnaround Time은 Process의 끝나는 시간을 기점으로 하기 때문에 각 Process의 끝나는 시간의 sum / process의 수이다. 결과를 보면 Response Time의 측면에서 preemption 기법이 훨씬 좋다는 것을 파악할 수 있다. 그러나 주의할 것은 항상 좋은 것은 아니다. FIFO나 Embeded System에서는 preemption기법을 사용하지 않는 것이 더 좋을 수도 있기 때문에 OS는 좋은 스케줄링 알고리즘을 채택해야한다. 결과적으로 이 Time Sharing System이 발전해나가면서 CTS, MULTICS, UNIX, LINUX등으로 발전해나갔다.
Wrapping Up
Multiprogramming 및 Time Sharing의 어려운 요구 사항을 충족하기 위해 OS가 5가지 주요 성과를 달성했다.
- Processes
- Memory Management
- Information Protection and Security
- Scheduling and Resource Management
- System Structure
이에 대해서는 다음 포스팅에서 차차 배워가면서 OS는 뭘 하는지 어떤 작업을 수행하는지 알아보자.
저작권 문제와 지적은 환영입니다.
Reference
William Stallings. (2018). Operating Systems: Internals and Design Principles (8th Edition): Pearson.
'Univ > Operating System(OS)' 카테고리의 다른 글
| [OS] System Call (POSIX API) (0) | 2022.07.25 |
|---|---|
| [OS] Resource Protection (Kernel Mode, Timer) (0) | 2022.07.21 |
| [OS] Operating System Overview I (Intro) (0) | 2022.07.18 |
| [OS] Computer System Overview IV (I/O Device) (0) | 2022.07.15 |
| [OS] Computer System Overview III (Memory Hierarchy) (0) | 2022.07.11 |


