
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 백준
- coding
- 구현
- 브루트포스
- Stack
- 코테
- 정석학술정보관
- 그래프
- 자료구조
- 컴퓨터공학과
- 북리뷰
- 스택
- 알고리즘
- 오에스
- c++
- cs
- OS
- bfs
- DP
- vector
- 너비우선탐색
- 정석
- Operating System
- 코딩
- 문제풀이
- 컴공
- 개발
- 오퍼레이팅시스템
- Computer science
- 컴공과
- Today
- Total
Little Jay
[OS] Computer System Overview III (Memory Hierarchy) 본문
[OS] Computer System Overview III (Memory Hierarchy)
Jay, Lee 2022. 7. 11. 16:09Memory Hierarchy

메모리는 CPU의 작업공간이다. Processor가 성능을 최대한으로 내려면 Memory의 속도 역시 중요하다. Memory는 장치의 특성에 따라 피라미드 형태로 계층구조를 그릴 수 있다. 위의 그림을 보면 레지스터, SRAM, DRAM, DISK, Secondary Memory의 순으로 피라미드 형태로 나눌 수 있는 모습을 볼 수 있다. 피라미드가 점점 내려가면서 가격적인 측면과 용량적인 측면에서 이득을 많이 볼 수 있지만, 반면 속도가 점점 내려가고 이에 따른 대역폭도 내려간다. 우리는 이러한 관계를 메모리 계층구조라고 부른다. 그러나 우리는 ideal하게 빠른 속도의 High Level Memory와 Low Level Memory의 가격과 용량을 얻고 싶다. 따라서 우리는 이 Memory Hierarchy를 통해 이를 해결 할 수 있다. Memory Hierarchy의 목표는 하나의 Virtual Memory 기술로서 빠른 속도의 High Level Memory와 Low Level Memory의 용량과 가격의 두 마리의 토끼를 잡는것을 목표로 한다. 이것이 가능한 이유는 바로 Locality라는 집중화의 원리이다. 이는 지역성이라고도 불리는데 이 원리는 두가지 측면에서 바라볼 수 있다.
- Temporal Locality (locaity in time): 시간적인 측면에서 바라보는 것이다. 예를 들어 프로그래밍을 할 때는 for, while등의 반복문을 많이 사용하게 되는데, 반복문에서는 한 번 참조된 항목은 다시 활용되기에 용이하다. 이러한 구조를 Temporal Locality라고 한다.
- Spatial Locality (locality in space): 공간적인 측면에서 바라보는 것이다. 메모리는 Linear하게 주소가 구성되어 있다. 따라서 배열을 예를 들자면 배열은 메모리에 연속적으로 위치하고 있다. 이 배열은 한번만 사용되는 것이 아니라 그 주소의 주변을 접근하는 경향이 매우 높다. 이러한 구조를 Spatial Locality라고 한다.
이러한 Locality를 활용하면 특정 주소에 매번 접근하는 것이 아니라 특정 주소를 매번 반입해서 올리는 것이 아니라 예측할 수 있는 것이다. 아래의 그림은 시간에 따른 메모리 접근 영역에 대한 상관관계를 보여준다. 출처는 아래에 적혀있다. 그림을 보면 Processor는 사용하는 메모리 주소만 사용한다는 것을 볼 수 있다. 따라서 여기에 예측을 잘 하게 되면 CPU가 Memory에서 주소들을 반입하는 빈도수를 줄여 더 빠른 Utilization을 보일 수 있는 것이다.

Cache
이러한 Memory Hierarchy 기술이 잘 적용된 것이 Cache이다. Cache의 목표도 명확하다. SRAM의 빠른 속도와 DRAM의 용량과 비용의 이득을 취하는 것이다. 또한 Cache는 Processor로 하여금 Memory Bandwidth 즉 소비되는 메모리의 대역폭은 ISA의 변환 없이 감소시킬 수 있다. 캐시는 CPU에만 붙어 있는 것이 아니라 Virtual Memory에도, Network Buffer Cache 등등 많은 곳에서 활용되고 있다.
캐시는 Memory 주소에 대한 복사본을 Block 단위로 가져오고 있다. Block단위로 가져오는 것은 Locality를 활용하기 위함이다. Processor는 Memory를 읽기 전에 먼저 Cache에 방문해 Cache에 원하는 Data Block이 있는지에 대한 여부를 먼저 확인한다. Data가 만약 있다면 캐시에서 바로 가져와서 읽어버리고 없다면 Memory로 가서 데이터를 Cache에 반입하고 읽게된다. Cache에 원하는 Data가 있다면 이를 'Hit'이라고 부른다. 이때 Hit Time은 Hit이 되는 시간이며 Hit Rate / Hit Time = Hit Ratio가 된다. 반대로 'Miss'는 원하는 주소가 Cache가 아닌 Memory에 있는 경우이다. Miss Rate는 당연히 1 - Hit Rate가 된다. 아래의 그림을 보자.
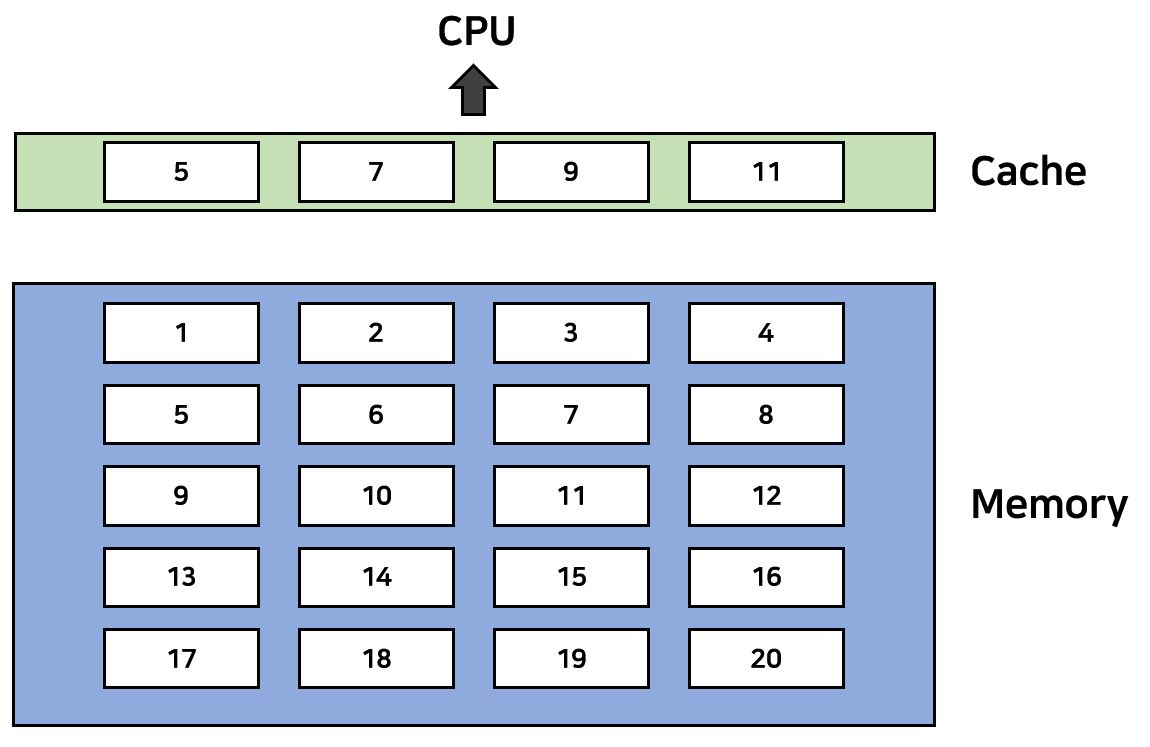
만약 여기서 CPU가 5번을 Request한다고 가정하면 이는 메모리에 있기에 Hit이다. Cache에 있다면 메모리까지 내려가지 않아도 되기 때문에 바로바로 처리할 수 있다. 그러나 CPU가 17번 Block을 Request한다면 어떻게 될까? Cache에서는 당연히 Miss가 발생했다. 따라서 우리는 Cache를 바라보는 것이 아니라 얼른 System Bus를 타고 Memory를 타고 내려와서 해당 블럭을 찾고 Cache에서 적절한 Victim을 찾고 이를 Replace한 후 CPU에게 그 내용을 전송한다.
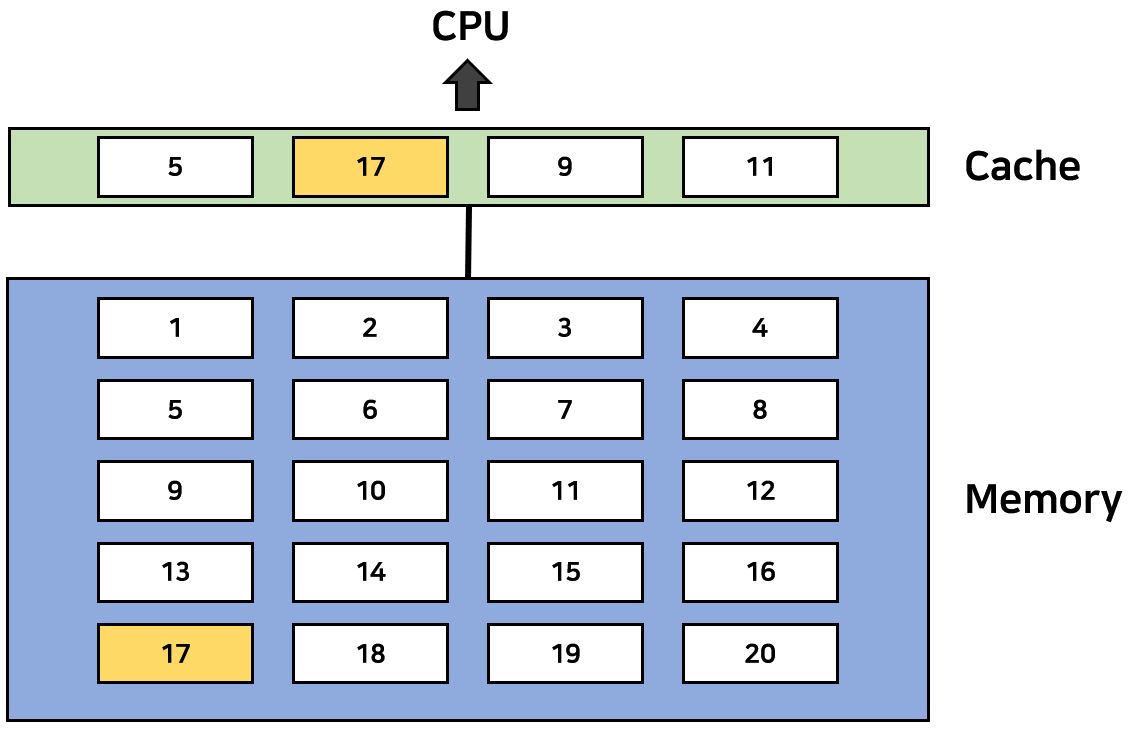
위 그림에서 보았듯이 Miss가 일어날 때는 Cache에 있는 적당한 Victim을 선택해야한다. 그렇기 때문에 Cache에서 중요한 기술 두 가지가 있는데, 이는 Placement Policy와 Replacement Policy이다. Placement Policy는 가져온 블럭을 어디에 위치시킬 것인지, Replacement Policy는 어떤 Victim을 선정할 것인지 결정하는 Policy이다.
SRAM과 DRAM의 속도 차이는 매우 크다. 중요한 것은 우리는 메모리 계층구조를 사용하기 때문에 Memory에 접근하는 시간을 획기적으로 줄일 수 있다. 그렇기 때문에 상황을 가정하고 Data에 접근하는 평균시간을 구해보자. Cache에 Data를 접근하는 시간은 0.1us가 걸린다고 가정하고, Memory에서 Data를 접근하는 시간이 1us가 걸린다고 가정해보자. 만약 SRAM에서의 Hit Ratio가 0.9라고 해보자. 그렇다면 평균시간 T는 T = (0.9)(0.1us) + (0.1)(0.1us + 1us) = 0.09us + 0.11us = 0.2us이다. 우리는 이렇게 Memory Hierarchy 구조를 통해 Memory에 접근하는 시간을 획기적으로 줄일 수 있다. 매번 시스템 버스를 타면서 1us가 걸리는 것보다 평균적으로 0.2us가 걸리며, 또한 Hit이 일어났을 때에는 0.1us밖에 걸리지 않기에 이렇게 접근하는 방식은 매우 효율적이라고 할 수 있다.
Cache Organization
이제 중요한 것은 Cache를 어떻게 구성할 것인가에 대한 문제이다. Cache가 어떻게 구성이 되어있는지에 따라서 효율적으로 비효율적으로 동작이 가능하다.
Directed Mapping
간단한 방식이다. Cache에 들어올 수 있는 Memory 주소를 미리 지정해주는 것이다. 예를 들어서 16byte의 메모리와 4byte의 Cache가 있다고 하자. 하나의 Block를 1byte라고 가정하나다면 modulo 연산을 통해 (Mem Address) % (Cache Slots)로 올 수 있는 주소가 결정된다. 0, 4, 8, 12는 Cache의 0번방에 1, 5, 9, 13은 Cache의 1번방에 이런식으로 말이다. 이렇게 되면 Replacement Policy는 정할 필요가 없다. 우리는 Victim을 이미 그 자리 자체로 지정해놓았기 때문에 단순히 Swap Out만 시켜주면 된다. 그러나 이 방식의 문제는 특정 주소만 사용이 된다면 특정 Cache Block만 사용하는 것이기 때문에 Hit Rate가 낮아져서 빈번하게 Memory에 접근해 자주 Swap Out될 수 있다. 예를 들어 0, 4, 0, 4, 0, 4가 계속 들어오게 된다면 계속 Cache Block은 Swap Out되어 오히려 성능이 떨어질 수 있다.
Fully Associative Mapping
Directed Mapping보다 더 간단한 방법이다. 정말 단순히 무지성으로 빈 Cache가 있으면 넣고, 적절한 Replacement Policy에 의해 Victim만 선정해서 바꾸면 된다. LRU든 Second Chance든 Victim만 잘 고르면 된다.
N-Way Sey Associative Mapping
위 두개의 절충안이다. N이 2 이상일 때 사용한다. 들어가기에 앞서서 Tag라는 용어가 있다. Tag는 수화물에 붙이는 꼬리표처럼 주소를 식별해줄 수 있는 것이다. 이제 N의 수 만큼 Set에 들어갈 수 있다. 표현력이 부족하여 그림을 같이 보겠다. 아래의 그림은 Directed Mapping과 2 way의 비교이다. 먼저 Directed Mapping을 보자. 01000이 들어왔는데, 하위 3bit인 Set이 비었으니 들어간다. 10100도 잘 들어가고 00110, 01011도 잘 들어가게 된다. 문제는 01110이 들어왔을 때이다. Set이 110이지만 이미 이는 Tag가 00인 주소가 먼저 들어가 있기에 이를 Replace해주어 들어가게 된다. 따라서 아래의 왼쪽 그림과 같이 나오는 것이다. 이번에는 옆의 2 Way 방식을 보자. 이번에 Set Bit이 2bit이다. 이때 하나의 Set에 두 개씩 들어갈 수 있다는 것이다. 따라서 이번에는 모든 주소들이 문제없이 잘 들어가게 된다. 2 Way는 Hit Ratio를 높일 수 있다는 장점이 있긴하지만, 각 Set이 하나라도 비었는지 확인하는 탐색비용(비교 비용)은 증가하지만 이는 Temporal Locaily를 높일 수 있다는 장점 또한 보유하고 있다.
결과적으로 Cache를 읽을 때에는 아래의 그림처럼 동작하게 되는 것이다.

Cache Write
사실 Cache를 읽기만 한다면 전혀 문제가 생기지 않는다. 그러나 Cache에 Write가 된다면 여기서 새로운 메커니즘들이 동작하게 된다. Cache는 일반적으로 메모리의 복사본을 저장하고 있다. 우리의 모든 Operation들을 Cache에서 하고 있는데 메모리와 Cache의 내용이 서로 달라서 문제가 생기는 경우가 발생할 수도 있다. (DMA Access라던지) 따라서 Cache에 Write로 데이터에 대한 변화가 생기면 당연하게도 Memory에 변화가 필요하다. 이를 수행하는 두 가지 Policy가 존재한다. 하나는 Write Through 방식이다. 이 방식은 Cache에 변화가 생기면 바로바로 Memory에 적어주는 방식이다. 항상 일관성을 유지시켜준다는 장점이 있지만 이렇게 바로바로 써줄꺼면 Memory버스를 계속 타서 적어줘야하는데 이는 매우 느리고 Memory Traffic이 증가한다는 치명저인 단점이 있다. 반대로 Write Back이라는 방식도 있다. 그냥 Cache에서 계속 사용하다가 Data Block이 교체될 때 그체소야 Memory에 Write해주는 방식이다. 이를 위해서는 Cache에 변화가 일어났는지에 대한 Dirty Bit이 하나 추가적으로 필요하며, 이를 구현하기 위한 난이도도 높을 뿐더러 일관성의 문제도 발생할 수 있다. 그러나 역시 빠르다는 장점이 우선시된다.
Reference
Gideon Glass, Pei Cao. (1997). Adaptive page replacement based on memory reference behavior. ACM SIGMETRICS Performance Evaluation Review, 25(1), pp. 115-117.
William Stallings. (2018). Operating Systems: Internals and Design Principles (8th Edition): Pearson.
'Univ > Operating System(OS)' 카테고리의 다른 글
| [OS] Operating System Overview II (Evolution through History) (0) | 2022.07.19 |
|---|---|
| [OS] Operating System Overview I (Intro) (0) | 2022.07.18 |
| [OS] Computer System Overview IV (I/O Device) (0) | 2022.07.15 |
| [OS] Computer System Overview II (Interrupt Handling with Linux Codes) (0) | 2022.07.09 |
| [OS] Computer System Overview I (Components, Processor, PIC) (0) | 2022.07.08 |


