
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 컴공과
- 문제풀이
- 오에스
- Operating System
- 개발
- 알고리즘
- DP
- 브루트포스
- 그래프
- 북리뷰
- 스택
- 정석
- cs
- 구현
- 코딩
- Computer science
- c++
- 코테
- 백준
- 정석학술정보관
- 자료구조
- OS
- bfs
- coding
- Stack
- 오퍼레이팅시스템
- 컴퓨터공학과
- 컴공
- 너비우선탐색
- vector
- Today
- Total
Little Jay
[OS] Computer System Overview IV (I/O Device) 본문
I/O Controller
I/O Device와 Processor가 통신하기 위해서는 특정한 Interface가 필요하다. 이 Interface는 I/O Controller이며, CPU와 I/O Controller는 System Bus를 통해서 Data를 주고 받는다. System Bus라고 하면 Data전송을 위한 HW Line이며 이는 중요한 시스템 자원이다. 이 System Bus는 최소 3개로 이루어져 있다.
- Address Bus : Src, Dst를 지정해주는 Bus이다
- Data Bus : 실제 Data를 전송해주는 Bus
- Control Bus : 어떤 Operation을 수행해야하는지 알려주는 Bus이다
따라서 I/O Controller들은 이 Bus를 통해 CPU 대신해서 I/O 들을 Control하는 것이다. CPU가 I/O까지 담당하게 되면 I/O를 기다리는 시간때문에 idle해질 수 있다. 이 Bus들은 CPU에 붙어 있는 레지스터로서 HW Line이 붙어있는 것이다. 만약 복잡한 Device가 있다면 당연히 더 많은 Control, Status Register와 Bus가 필요할 것이다. (ex. CISC)
I/O Address Space
I/O Device는 당연하게도 주소를 가지고 있다. 이 주소들의 집합이 Address Space이다. I/O Address Space를 구현하는 방식에는 두 가지가 있는데 하나는 Port-Mapped I/O이다. I/O Device의 주소는 우리가 사용하는 Main Memory와는 독립적으로 존재한다. 이는 독립적이기 때문에 Isolated Address Space라고 불리기도 한다. 특히 x86 Intel Processor 계열에서 이 방식을 주로 사용한다. I/O 와 Memory 가 분리되어있어 전체 메모리를 사용할 수 있다. 그러나 이제는 Memory의 가격이 많이 싸지고 용량도 늘어나기 때문에 큰 문제는 되지 않는다. x86 아키텍쳐에서는 IN, OUT 이라는 Assembly 명령어를 통해서 언제 I/O가 발생하는지 빠르게 파악하는데 용이하다. 또한 lw, sw같은 메모리 관련 opcode가 들어오게 된다면 관련 영역만 건들면 되기 때문에 Memory적으로 Collision이 일어나지도 않는다. 다시말해 Instruction이 별도의 Memory와 Mapping되어 있다고 할 수 있는 것이다. 이 Assembly가 Trigger되면 별도의 Device Bus를 타고 작업을 수행하기에 응답시간이 빠른 편이다. 작업을 수행할 수 있는 I/O Device의 Range는 000~3FF 정도인데 이와 관련해서는 Silverschatz 교재의 12.2번 그림을 참고 하면 되겠다. 다른 하나는 Memory-Mapped I/O이다. Port-Mapped I/O와는 반대로 실제 Main Memory와 같은 공간에서 Address를 사용한다. 따라서 구조가 간단하다. 주의해야 할점은 I/O를 위한 주소는 일반 Physical Memory 측면에서는 사용이 불가능해야한다. I/O를 위한 Space를 남겨놔야 해야하기 때문이다. 그리고 일반 Instruction을 사용하게 되는데, 임베디드 시스템 구현시 용이하다.(저렴하고 쉽다) 주소와 데이터 버스를 많이 사용하게 되어, 매핑된 장치에 접근하는 속도가 느리다는 단점이 있다. 물론 현대의 Computer System에서는 이 두가지를 동시에 사용하는 Hybrid적인 방식을 선택하기도 한다.
I/O Comunication Techniques
Programmed I/O (Polling I/O)
CPU에서 실제 port register들을 직접 접근하는 방식이다. Data, Status, Command Register에게 Direct한 접근을 한다. while문을 통해서 Status가 Busy하지 않을때까지 기다렸다가 idle해지면 다시 I/O를 수행하고, 다시 wait(polling)하는 방식이다. 이는 전통적인 Busy-Waiting 방식을 통해서 구현이 된다. 그러나 Busy-Waiting한다는 것은 CPU가 idle해질 수 있다는 뜻이다. 따라서 이에 따른 Utilization의 감소가 일어날 수 있다. 물론 I/O Device가 빠를때에는 괜찮은 방법이기도 하다. 따라서 READ하는 Operation을 글로서 써보면 아래와 같다.
- Host(CPU)가 READ명령을 I/O Module에 전송한다.
- I/O Controller가 이 Command Register을 읽고, Command를 읽는다.
- Status-Checking Loop(While)에 들어가서 Ready 상태이면 I/O를 처리하고, Busy 상태라면 일정 시간 기다린 후 다시 Status를 Check하게 된다. 이때 Check를 하는 주체는 CPU가 되겠다.
- I/O를 처리하는 것은 I/O Module로 부터 읽고 Memory에 Write해준다.
이 방식은 결과적으로 Context Switching을 유발하기 때문에 Data가 Loss될 수 있으며, Device가 만약 느리다면 비효율 적인 방식이다. 그림으로 순서도를 만들면 아래와 같다.
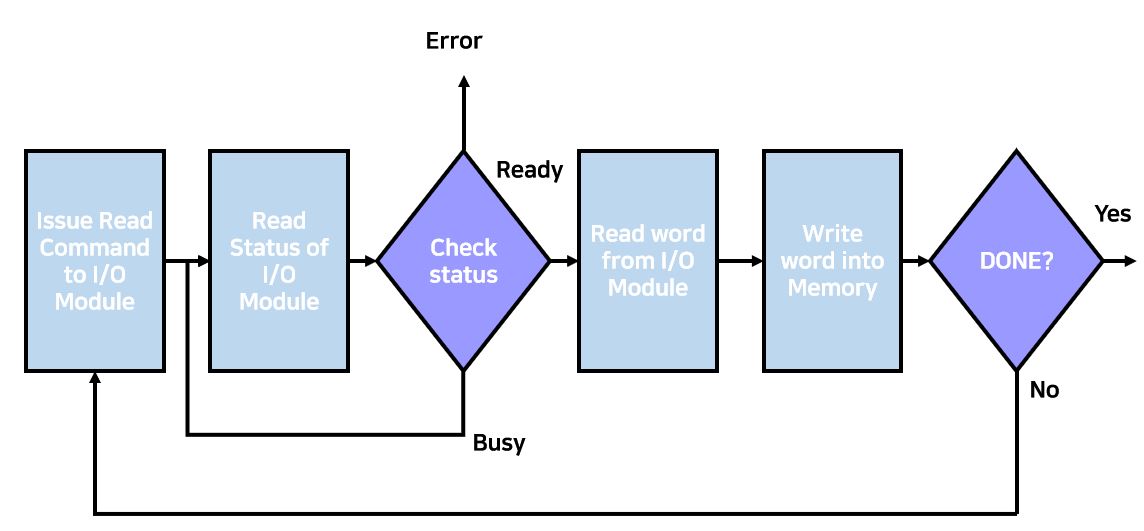
Interrupt-Driven I/O
우리가 앞에서 그리고 시스템 프로그래밍에서 다루었던 Interrupt를 활용하는 방식이다. Interrupt를 사용하겠다는 것은 Busy-Waiting하는 구간을 없앤다는 것이다. CPU의 Clock Speed를 생각하면 얘를 놀리고 있는 것보다는 일을 시키는 것이 훨씬 효율적이기 때문에 이를 사용하는 것이 좋다. 다시 정리하자면, Check Status에서 Busy하다면 Loop으로 들어가는 것이 아니라 다른 작업들을 Concurrently하게 수행하다가 Interrupt가 발생하면 다시 돌아와서 Interrupt Handler ISR로 가서 수행하고 작업을 하면 된다. Polling I/O 방식과 공통점이라면 Word단위로 작업을 한다는 것이다. 이는 Character 기반 Device에서 많이 사용된다. 차이점이라고 하면 Loop이 없기 때문에 훨씬 효율적이지만 Context Switching의 비용을 고려해야 한다는 점이다. Flow Char는 아래와 같다.
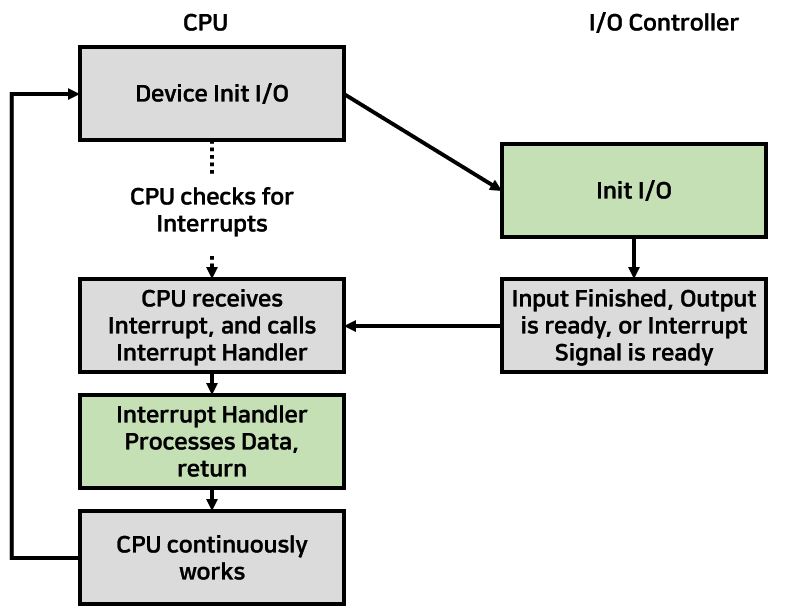
DMA (Direct Memory Access)
많이들 들어본 단어일 것이다. HDD같이 큰 데이터 처리에 대해서는 Block 단위의 Operation이 필요하다. Block은 Word 보다 사이즈가 훨씬 크다. 따라서 이 사이즈에 대해서 Loop을 돌리거나 Interrupt를 처리한다면 이에 대한 비용이 너무 많이 들 것이다. DMA의 목표는 CPU의 개입을 최소화 시키는 것이다. I/O Controller가 Memory에 Direct Access를 수행해서 Memory에 Write해준다면 CPU 입장에서는 매우 편할 것이다. CPU가 우선적으로 DMA Controller에게 Command Block을 전달한다. 여기에는 Src, Dst Addr, PSW, Buffer 크기 등이 담겨있다. 이 부분을 제외하면 CPU가 DMA를 수행하는 중 개입하는 일은 없다. DMA 기법은 I/O Controller와 분리되던지, 아니면 통합된 상태로 유지될 수 있다. 중요한 것은 고용량의 Data를 고속처리해준다는 것이다.
SMP(Symmertric Multiprocessor) & APIC(Advanced PIC)
SMP를 직역하면 대칭적 다중처리기라고 한다. 즉 다수의 Processor가 협업해서 하나의 Program을 수행하는 것이다. 따라서 이를 위해서는 각 Processor들은 Shared Memory를 통해서 작업을 수행해야한다. 또한 CPU들이 대등한 조건으로 작업을 해야 효과적으로 동작할 수 있다. (Master-Slave 관계가 아닌 평등한 조건이어야한다. I/O Device는 따라서 각 CPU들에게 Shared되거나 Local하게 동작한다. Local하게 동작하는 것의 예는 System Timer가 있다. System Timer에 대해 잠깐 소개하고 넘어가자면, Timer는 주파수 즉, Frequency를 적절히 설정해서 TIC를 알려준다. 이를 통해서 상대시간을 알 수 있다. 상대시간을 아는 것은 Scheduling Algorithm에서 중요하게 작동하는데, 이는 추후에 Scheduling Part에서 자세히 한번 다뤄보겠다. 어째뜬 우리가 초점을 맞춰야하는 것은 Shared I/O Device이다. 우리는 앞서서 PIC이 외부 Device의 Interrupt, Interrupt Vector, 그에 따른 우선순위 조정들을 한다고 배웠다. 이 PIC은 하나의 Processor에 대해 있다고 했지만 이제는 문제가 바뀌어 공유되고 있는 External Device에 대해서 이를 조정해고 각 Processor에 맞게 배분할 필요가 있다. 마우스, 키보드, 모니터 등등 공유되고 있는 외부 디바이스에 대한 처리를 돕는 PIC이 APIC이다.
예를 들어서 마우스를 Click하는 Event가 발생한다고 하자. 이 Interrupt를 처리하기 위한 Handler을 수행해야 하는데, 이 ISR도 결국 명령어의 집합이다. 따라서 이제는 어떤 CPU가 이를 담당할지에 대한 문제, Distribution에 대한 문제가 발생한다. 보통은 Idle한 CPU 즉 Counter를 설정해서 상대시간을 파악 후 이 IRQ를 evenly하게 나눠주는 Dynamic한 방법을 사용하기도 한다. 이는 어디까지이나 예시이고 각 Architecture마다 다를 수 있다.
APIC은 Local하게 있을 수도 있는데 이는 Global APIC에서 전달된 Interrupt와 Local에서 연결된 Interrupt를 연결시켜준다. APIC은 Multiprocessor 환경에서 어느 CPU에 Interrupt를 전달할 것인가의 기능과 Local APIC에세 Signal을 전달해주는 두 가지의 역할을 가지고 있다고 보면 될 것이다. 또한 Local APIC은 System Timer와 연결되어 Shared External Device에 대한 Interrupt를 Handling할 수 있는 하나의 기준을 세워줄 수 있는 것이다.
Reference
William Stallings. (2018). Operating Systems: Internals and Design Principles (8th Edition): Pearson.
'Univ > Operating System(OS)' 카테고리의 다른 글
| [OS] Operating System Overview II (Evolution through History) (0) | 2022.07.19 |
|---|---|
| [OS] Operating System Overview I (Intro) (0) | 2022.07.18 |
| [OS] Computer System Overview III (Memory Hierarchy) (0) | 2022.07.11 |
| [OS] Computer System Overview II (Interrupt Handling with Linux Codes) (0) | 2022.07.09 |
| [OS] Computer System Overview I (Components, Processor, PIC) (0) | 2022.07.08 |


