
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 구현
- Operating System
- 브루트포스
- 정석학술정보관
- 오퍼레이팅시스템
- 북리뷰
- 알고리즘
- 스택
- 정석
- 컴공
- Stack
- 자료구조
- DP
- 코딩
- 그래프
- Computer science
- 컴공과
- OS
- 너비우선탐색
- coding
- vector
- 코테
- 개발
- cs
- 컴퓨터공학과
- 오에스
- 문제풀이
- bfs
- 백준
- c++
- Today
- Total
Little Jay
[OS] Thread I (Introduction, Advantages, Challenges) 본문
[OS] Thread I (Introduction, Advantages, Challenges)
Jay, Lee 2022. 8. 22. 16:13Thread
우리는 지금까지 Process를 실행중인 Program. Program의 Execution Sequence이면서 System Resource를 다루는 단위라고 언급을했다. Process에는 두 가지의 특성이 있었는데, 하나는 자원 소유권의 단위로서 memory, heap, global vars, I/O등을 담당하였고, 실행단위의 특성으로서는 Process를 Scheduling의 단위로서 바라보아 Execution State와 Priority를 가지고 있었다. 그러나 이제는 Execution Sequence를 담당하는 주체를 Process가 아닌, Thread로 바라볼 것이다. 간단하게 정리해보자면 Execution Environment, 즉 환경을 Process가, 그 환경 안에서 Execution Sequence를 Thread가 담당하게 되는 것이다.
Multithreading
현대의 모든 OS들은 Multithreading을 지원한다. Multithreading은 한 프로세스 내에서 다수닁 Thread들이 존재한다는 것이다. OS로 하여금 여러개의 Concurrent한 Path를 지원하는 능력이 멀티 쓰레딩의 힘이다. 이때 Threads들은 Single Process내에서 돌고 있다고 가정을 했는데, Process는 Thread가 동작할 수 있는 환경이다. 그렇기에 Thread들은 Resources들을 Share하게 된다.
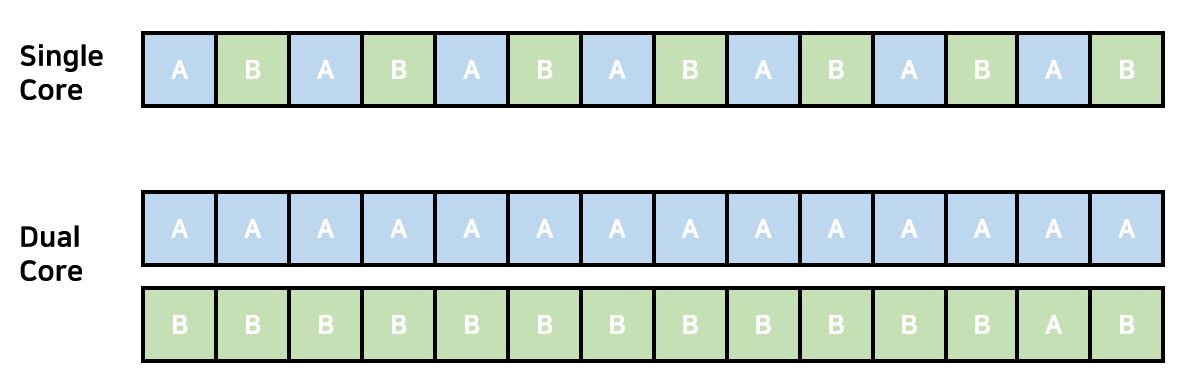
본격적으로 들어가기에 앞서서 용어에 대한 정리가 필요할 것 같다. 우리가 일반적으로 Concurrency와 Parallelism을 비슷하게 동의어처럼 사용하기도 하는데 이는 명백히 다른 단어이다. Concurrency는 동시성, 병행성의 의미를 가지고 있는 단어이다. 따라서 이는Task, Process, Thread들이 있을 때 이것들을 동시에 진행시키는 능력이다. 반대로 Parallelism은 병렬성으로서 동시에 실행시키는 능력이다. 쉽게 말하자면 Concurrency는 Single Core에서 Task들은 Interleaving하게 진행이 된다. 여기서 Concurrency가 적용이 되는 것은 User들로 하여금 Program들이 끊임없이 진행되고 있는 것 처럼 보이게 하는 Illusion을 제공하는 것이다. 반대로 Parellelism은 Multicore라고 생각하면 편하다. 동시에 서로 다른 Job들을 Overlapping하여 수행하는 것이다. 따라서 Concurrency는 Parellelism과 관계 없이 Job들을 끊임없이 Interleaving하게 수행하는 것이다. 따라서 Single Core에서 Parell이라는 단어는 나올 수 없다.
Motivation
쓰레드를 이야기 할때는 Web Server에 대한 예시가 정말 많이 나온다. 쓰레드의 등장 배경은 Application이 여러개의 task를 가지고 있을 때, task가 Blocking 여부에 상관없이 그냥 진행시키기를 원하는 것이다. 간단히 예를 들어보자면 while문 앞에 a, b 함수가 있다고 해보자. 만약 b라는 함수 호출이 엄청나게 많은 일들을 하게 된다면 그만큼 a는 b가 끝날때까지 기다려야 한다. 이러한 상황은 Web Server에서도 발생한다. Client가 Request를 보내게 되면 Server에서는 Accept하고 Recv&Send하는 서비스처리에 진입한다. Single Thread에서 서비스처리를 하는 도중에 DB 접근에 시간을 많이 소요하는 등의 이유로 이 대기 시간이 길어지게 된다면 Server는 Client의 다른 Request를 받지 못하게 된다. 물론 이를 처리해주는 방법 중 하나로는 앞에서 다룬 Fork를 활용한 Multiprocessing 방법으로 해결할 수 있다. 그러나 Multiprocessing 방식은 Overhead가 Multi-threading보다 상당히 높다. 따라서 현대에 와서는 이를 Multi-Threading 방식으로 해결한다. 서비스처리해주는 부분을 새로운 Thread에게 맡겨버리고 Main Thread는 계속 Accept하면 되기 때문이다.
Advantages
본격적으로 Multi-Threading을 사용하는 장점에 대해서 이야기 해보자.
Responsiveness
가장 처음으로 다뤄볼 장점 중 하나는 응답성이다. 방금 웹 서버 예제에서 다룬것 처럼 Server에 요청을 보내면 서비스로직을 처리하느라 기다리는 시간이 필연적으로 발생한다. Latency는 필연적으로 발생하게 된다. 만약 Thread를 사용하지 않게 되면 우리는 이 Logic를 처리하는 데 필연적으로 두 번의 System Call(RPC)이 발생하게 된다. 그러나 Thread를 사용하면 Accept는 Accept대로, Service처리는 서비스 처리대로 다른 Thread에서 처리하도록 하면 대기 시간을 획기적으로 줄일 수 있다. 따라서 Syscall로 인해 Block되든, 아니면 Job이 Lengthy하든지간에 상관없이 Program을 계속해서 Run 시킬 수 있도록 하여 매우 뛰어난 응답석을 보이는 것이다. 참고로 말하자면 RPC라고 하는 것은 원격에 있는 System에 접근하는 것을 Syscall로 하는 것 같은 Illusion을 제공하는 방식이다.

Economy of Time
경제적 측면에서 바라봐도 Thread를 사용하는 것이 훨씬 유리하다. 특히 하나의 Process를 만드는 것 보다는 Thread를 생성하는 것이 훨씬 경제적이다. 일반적으로 새로운 Process를 만드려면 Fork-Excv 구조를 활용해야한다. Fork를 하게되면 Main Memory에 PCB, Stack, Data 영역 등 새로운 Process Image가 생성된다. 그러나 Thread를 새롭게 생성하는 것은 해당 Process 내에서 TCB(Thread Control Block)만 생성하면 된다. 이는 Process Image 전체를 유지하는 것 보다 사이즈도 작으며 매우 간편하다. 어차피 Thread는 Data를 Process 내에서 공유하기 때문에 Data에대한 Copy가 이루어질 필요가 없다. 이는 생성, 종료면에서 매우 효율적이며 또한 Process 전체의 실행을 바꿔버리는 Context Switch보다 Thread Switch가 더 빠르다.
Resource Sharing
다음 이점으로는 자원 공유이다. 사실 이 부분이 득인지 실인지는 잘 모르겠지만 여튼 하나의 Process 내에서 Thread들을 Process의 Data를 공유한다. Data 부분의 전역변수들을 공유하게 된다. 일반적으로 Fork는 전역변수를 공유하지 않는다. Process이기 때문에 새로운 Data영역이 생성되어서 같은 이름의 변수를 사용하더라도 이는 다른 Data Block에 있기 때문에 서로 공유되지는 않는다. 자원의 공유라는 측면에서 바라볼 때 Process간의 Data공유는 어떻게 이루어지는지 궁금할 수도 있을 것 같다. Process들은 IPC(Inter Process Communication)을 활용한다. Socket이나 Shared Memory에서 주로 활용이 되는데 어찌되었든 IPC는 System Call이다. 따라서 이는 필연적으로 Mode Switch가 발생하게 되면 이에 대한 Cost가 발생한다. 반면 Thread는 주어진 Data Block에 있는 자원들을 활용만하면 되는 것이기 때문에 Cost는 매우 낮지만 이제는 동기화 문제를 살펴봐야 한다. 이 부분은 뒤에서 다루겠다.
Scalability
마지막으로 살펴 볼 장점으로는 확장성이 있다. Process를 더 작은 Task 단위로 조각을 낸 것이 Thread이다. 이 path를 Pararellism을 보장해주는 Multi-Processor와 잘 맞아 떨어져 Mapping이 된다. 다시말해서 Parallelism의 단위를 더 작게 만들 수 있다는 의미이다. 예를 들어 같은 Application을 이제는 Multi Core에서 Run 시킬 수 있는 것이다. 따라서 이러한 병렬적인 측면에서 Process보다는 Thread가 이점을 보인다.
Multi-Threading on Multi-Core
컴퓨터를 다뤄본 사람이라면 Amdahl's Law(암달의 법칙)이라는 것을 들어본 적이 있을 것이다.

암달의 법칙은 이상적으로 Processor가 늘어나면 그만큼 비례하여 성능이 늘어나는 것이 아니라 순차 실행영역을 제외한 나머지 부분에서의 성능 향상이 일어나는 것이다. 따라서 위 식에서 S는 순차적인 Serial 영역이기에 이보다 더 커질수는 없는 것이다. task, data, flow 등에 의존성이 존재하기 떄문에 Parallel하게 적용할 수 없는 부분이 존재한다.
이와 마찬가지로 Thread에도 Optimal한 Thread의 수가 존재한다. 일반적으로 쓰레드를 많이 사용하면 그 만큼의 성능향상이 일어날 것처럼 보이지만 무한정 늘리는 것은 좋지 않다. 우리가 CPU를 살때도 N-Core, M-Threads라고 적혀있는 것을 확인할 수 있는 것을 볼 수 있다. Process control and scheduling issues for multiprogrammed shared-memory multiprocessors 라는 학술지에 보면 Threads와 Speedup의 상관관계를 분석을 해 놓았다. 출처는 아래에 적어놓겠다.

쓰레드는 결국 Re-Scheduling에 따른 Burden이 존재한다. 다시말해 Switching Cost가 있다는 것이다. 예를 들어 동일한 작업을 한번의 iteration으로 끝낼 수 있다면 iteration을 사용하면 된다. 반복횟수가 10이라면 while(t--)같이 간단하게 할 수 있는 것을 쓰레드를 10개를 만들어서 각각 작업을 하는 것은 오히려 비효율 적이며 성능 역시 떨어진다. 따라서 Optimal한 Thread의 수를 정해놓고 이를 맞추는 것이 일반적이다. 위의 그래프를 보면 Multicore에서 이상적인 Thread의 수는 8개 정도이다.
Programming Challenges
그러나 역시 Thread를 구현하는 것은 결코 쉬운 일이 아니다. 첫 번째로 고려해야 할 점은 Task들을 식별하는 것이다. 병렬처리가 가능한지? 의존성은 없는지? 의존적이라면 쓰레드에서 구현은 어렵다. 다음으로는 Balance를 고려해야한다. Process도 각각의 Weight가 존재했다. Programmer들은 equal workload, equal size를 맞추는 것을 목표로 염두해야한다. 마지마긍로 정말 중요한 Data Dependency문제가 있다. 뒤에서 다룰 것이지만 Data 영역을 같이 사용하고 있기 때문에 동시 접근의 문제는 Race Condition으로 이어진다. 따라서 동기화 문제와 교착상태에 대해 심도있게 뒤에서 다뤄볼 것이다.
Reference
William Stallings. (2018). Operating Systems: Internals and Design Principles (8th Edition): Pearson.
Tucker, A and A Gupta. "Process control and scheduling issues for multiprogrammed shared-memory multiprocessors." SOSP '89: Proceedings of the twelfth ACM symposium on Operating systems principles, vol.1, 1989, pp. 159-166. DOI:https://doi.org/10.1145/74850.74866. https://dl.acm.org/doi/10.1145/74850.74866.



