
Little Jay
[OS] Process Scheudling IV (Scheduling with I/O, Time Quantum, Virtual Round Robin, MLFQ) 본문
[OS] Process Scheudling IV (Scheduling with I/O, Time Quantum, Virtual Round Robin, MLFQ)
Jay, Lee 2022. 8. 8. 15:04Scheudling Incorporating I/O
예를 들어 두 개의 Process가 있다고 가정하자. 하나의 Process는 5ms의 Service Time을 가지고 있고, I/O를 위해 25ms를 대기하고 있다. 반대로 다른 Process는 CPU-Intensive하여 Waiting이 발생하지 않는 CPU Burst적인 Operation을 한다고 하자. 아래의 그림은 각각 Time Slice가 50ms, 5ms일때의 상황이다.
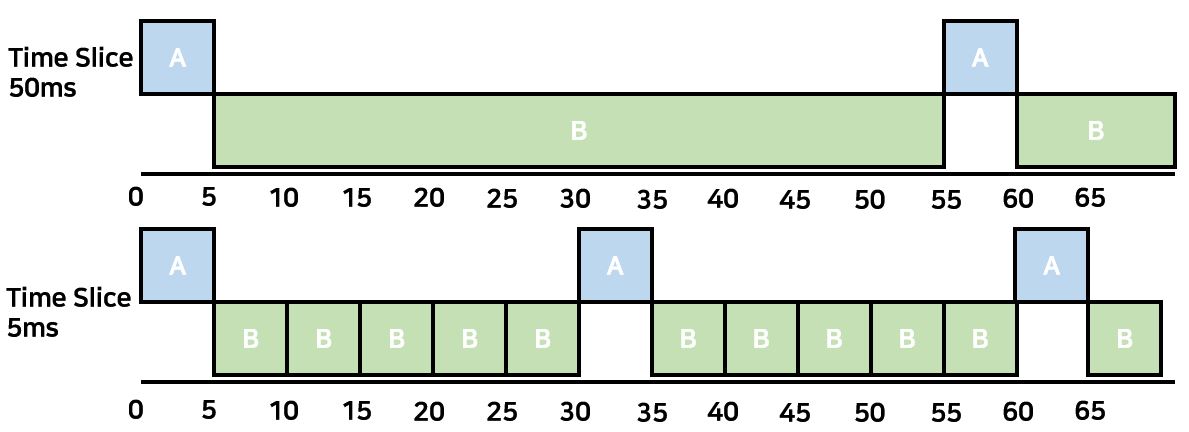
두 상황에서 CPU Utilization은 모두 100%이다. A가 I/O를 하고 있더라고 B Process가 Running되기에 Utilization 측면에서는 그 활용도가 100%가 된다. 그러나 주목해야할 점은 I/O Utilization이다. 첫 번째의 50ms의 Case에서 A Process의 I/O Utilization은 25/55이다. 결국 B가 Time Out되어 다시 A를 수행할 때까지 총 55ms를 기다리지만 실제로 A는 25ms밖에 기다리지 않는다. 반면 Time Slice가 5ms라면 A Process의 I/O Utilization은 25/30이 된다. A는 Blocked 상태에 25ms만 기다리면 다시 실행가능하기 때문에 I/O Utilization 측면에서는 Time Slice가 적은 것을 선택하는 것이 좋다. 따라서 Time Quantum이 줄어들 때 I/O를 함께 고려한 Utilization이 높아지게 된다. 그러나 Process B 같은 경우에는 계속해서 Time Out이 발생되기 때문에 Mode Switch에 대한 비용 역시 같이 고려해주는 것이 좋다.
Time Quantum
앞서서 Time Quantum을 잘 Design하는 것이 중요하다고 했다. 이를 Design하는 효율적인 방법 중 하나는 Time Quantum이 일반적인 Interaction 또는 Process Function 실행에 필요한 시간보다 약간 커야 한다는 것이다. 예를 들어 Interaction이나 Process Function보다 Time Quantum이 더 작다면 그 Process는 제대로 기능을 수행하지 못한 채 다시 들어올 때 수행햐 하므로 Job이 뒤로 밀릴 것이다. 따라서 Response Time보다 조금 더 Quantum을 크게 잡는것이 일반적인 Design Pattern이다.

Vitrual Round Robin
Virtual Round Robin은 Round Robin의 문제점을 잡기 위해 등장하였다. Round Robin의 문제점은 이 Quantum을 짧게 하면 결국 SPN처럼 동작하기에 CPU Bound Process들이 뒤로 밀리는 Convoy Effect가 발결될 수 있는 점이었다. 이 알고리즘은 Round Robin과 크게 다를 것이 없지만 새로운 보조 큐를 생성하게 된다. 만약 I/O Request 때문에 자신에게 주어진 Time Slice를 전부 소진하지 못하고 Block 상태로 들어간 Process들이 있을 것이다. 일반적인 RR이었다면 해당 Process들을 깨워줄 수 있는 Event가 발생하게 되면 Ready Queue의 맨 뒤로 돌아가 Front에 올때까지 기다려야 하지만, VRR에서는 새롭게 생성한 보조 큐에 넣게 된다. 따라서 이 Auxiliary Queue는 Time Slice를 다 소진하지 못한 Process들의 집합이 되는 것이다. 따라서 이 보조 큐에 어떤 Process가 들어오게 된다면 OS는 Ready Queue에 있는 Process를 고르는 것이 아니라 Auxiliary Queue에 있는 Process를 Running State로 고르게 된다. 이는 Simple 하면서도 Fairness를 어느정도 보장해주는 알고리즘이라고 할 수 있겠다. 아래의 그림처럼 도식화 할 수 있겠고,Fairness in processor scheduling in time sharing systems라는 논문에서 가져왔다. 출처는 아래에 적어놓겠다. 따라서 Time Slice를 전부 소진했는지 여부가 CPU, I/O Bound를 결정하게 된다. 일반적으로 CPU Bound Process는 Time Slice 전부 소진하여 Time Out되고, I/O Bound는 Time Slice를 전부 사용하지 못하는 경향을 보여준다.

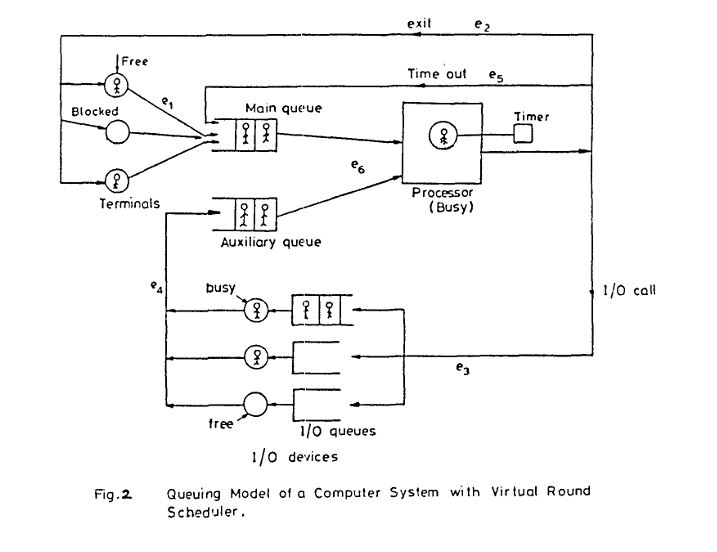
MLFQ (Multi-Level Feedback Queue)
Uni Processor에서 다룰 마지막 알고리즘이다. MLFQ는 Round Robin을 workload에 따라 Adaptive하게 사용하는 알고리즘이다. N개의 Queue가 있다고 가정하자. 그러면 Queue들에는 각각의 Time Quantum을 설정한다. Queue들에는 번호가 부여되는데 이 숫자가 낮을 수록 Priority가 높고, 숫자가 커질수록 Time Quantum은 Exponential하게 증가한다. Process들은 처음에 숫자가 가장 낮은 Queue에 동작한다. 이때 숫자가 가장 낮은 Queue에 있는 Time Quantum은 낮기 때문에 Service Time이 크다면 바로바로 Timeout이 될 것이다. 따라서 이 Time Slice를 전부 다 쓴다면 다음 Queue에 그 Process를 넣는다. 즉 우선순위를 낮춘다는 것이다. 따라서 종국에는 Process들이 각각의 Queue에 도달한다면 Processor는 Priority, 즉 번호가 낮은 Queue에 있는 Process들을 수행하는 것이다. 어차피 CPU Bound Process는 Batch Job일 확률이 매우 높다. 따라서 Time Quantum을 높여가면서 그러한 Process들은 FIFO처럼 동작시키는 것이 유리하다. Queue들에는 서로 다른 Scheduling Algorithm들을 적용시킬 수 있다. 따라서 번호가 낮은 Queue들에는 I/O Bound Process, Interactive Process들이 포진되어 있어 SPN, RR을 적용시킬 수 있고, 번호가 높은 Queue에는 Batch Jobs, CPU Bound Process들이 들어가 있어 RR, FIFO를 적용할 수 있게 된다. Process들은 Time Slice 소진 여부에 따른 Feedback을 받아 다른 Queue들로 이동하게 된다. 어쩌면 나중에 가면 번호가 큰 Queue에만 Process들이 가득할 수 있는데, 이때는 Aging 기법을 사용해서 Starvation을 완회시키기도 한다.

다음 포스팅에서는 Multiprocessor Scheduling에 대해 다루어 보겠다.
Reference
Haldar, S. & Subramanian, D. K. (1991). Fairness in processor scheduling in time sharing systems. ACM SIGOPS Operating Systems Review, 25(1), pp. 4-18.
William Stallings. (2018). Operating Systems: Internals and Design Principles (8th Edition): Pearson.
'Univ > Operating System(OS)' 카테고리의 다른 글
| [OS] Thread I (Introduction, Advantages, Challenges) (0) | 2022.08.22 |
|---|---|
| [OS] Process Scheduling V (Multiprocessor Scheduling, SQMS, MQMS, O(1), WFQ, CFS) (0) | 2022.08.10 |
| [OS] Process Scheduling III (Burst, Bound, FIFO vs SPN/RR, Round Robin Detail) (0) | 2022.08.06 |
| [OS] Process Scheduling II (Round Robin, SRT, HRRN) (0) | 2022.08.04 |
| [OS] Process Scheduling I (Intro, FIFO, SPN) (0) | 2022.08.03 |



