
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 코딩
- DP
- 오퍼레이팅시스템
- 정석
- 컴공과
- 그래프
- Stack
- 정석학술정보관
- OS
- 자료구조
- 구현
- Computer science
- 북리뷰
- vector
- 브루트포스
- 컴퓨터공학과
- 백준
- 문제풀이
- 오에스
- 컴공
- 알고리즘
- 코테
- Operating System
- 개발
- coding
- 너비우선탐색
- bfs
- 스택
- c++
- cs
- Today
- Total
Little Jay
[CS] Exceptional Control Flow: System Call - Computer System 3rd Edition by Bryant 본문
[CS] Exceptional Control Flow: System Call - Computer System 3rd Edition by Bryant
Jay, Lee 2022. 5. 13. 17:31User Mode vs Kernel Mode
프로세서는 기본적으로 mode bit를 제공해서 CPU가 어느 영역에서 task를 수행하는지 결정한다.
CPU에는 크게 두 가지 Mode로 구분할 수 있는데 이는 Kernel Mode와 User Mode로 구분한다.
- Kernel Mode: 커널 모드는 Supervisor Mode이다. mode bit가 set 되면 Kernel Mode에서 Instruction을 수행한다. Supervisor Mode이기 때문에 Kernel Mode는 모든 privileges를 갖는다. HW에 접근 즉 I/O Device와의 통신 등 아무런 제약 없이 Execute 한다
- User Mode: 유저 모드는 mode bit이 set 되지 않은 상태이다. 우리가 일반적으로 End-User 딴에서 사용하는 모드이며 많은 제약사항들이 존재한다. Kernel Mode와는 다르게 privilleges가 없는 상태이기 때문에 I/O Operation이라던지, mode bit 변경 등을 하지 못하고 메모리에 대한 접근도 제한이 된다.
x86 CPU에서는 3가지의 ring으로 privileges들을 할당할 수 있는데, Ring 0는 OS의 Kernel, Ring 1,2는 device drivers에게, Ring 3은 User가 사용하는 것이다. 그러나 대부분의 OS는 Ring 0, 3만 사용한다.
사실 이 Privilege를 사용하는 것은 자원의 Protection이라고도 볼 수 있을 것이다.
그렇다면 Protect 돼야 하는 자원들에는 무엇이 있을까?
- Privileged Instruction: 말 그대로 User가 막 사용해서는 안 되는 Instruction들이 있다. 그런 Instruction들은 안전하게 Kernel에서 사용해서 그 Privilege의 특성을 유지시켜야 한다. 막말로 User모드에서 Mode를 마음대로 바꾸게 되면 보안이라던지, 효율적인 측면에서 매우 안 좋아진다.
- Memory Access: Kernel에는 Kernel Stack 같은 메모리 영역이 DRAM상에 올라가 있다. User는 User의 영역에 집중해야지 다른 영역까지 문어발처럼 기웃거리면 안 된다. 따라서 Memory의 일정 부분은 User입장에서 Limit 돼야 한다.
- Access to HW: CPU는 그 속도가 매우 빠른 반면에 HW의 속도는 매우 느리다. User모드에서 마구잡이로 HW에 접근하려고 하면 속도의 저하로 이루어질 것이다. 따라서 Kernel모드에서 이를 처리함으로써 속도의 저하를 막아야 한다.
- Programmable Timer Interrupt: Timer Interrupt는 OS 파트에서 자세히 다룰 것이지만 timeout이 될 때 context switch가 발생할 수 있는데, 이를 User Mode에서 실행할 수 없는 노릇이다.
Control Flow
프로세서는 단 한 가지의 task를 수행한다. CPU는 컴퓨터가 시작하고 꺼질 때까지 단순하게 명령어를 읽고 수행하는 것, fetch - decode - execute를 하는 것이다. 이 Sequence를 Control Flow라고 명명한다.
우리가 Instruction 파트에서 보았듯이 이 Control Flow를 바꾸는 데는 Jump and Branch / Call and Return이 사용된다. 그러나 과연 이 두 가지 방법만으로 충분할까라는 질문을 해야 한다. 전혀 충분하지 않다. 우리는 코딩을 하면서 다양한 상황에 직면하게 된다. Division by Zero라던지, page fault, System Timer 문제 등 System State가 정말 다양하게 바뀌는데 Jump and Branch / Call and Return만 가지고는 이 변화에 유연한 대응을 펼칠 수 없다.
그렇기 때문에 Exceptional Control Flow가 필요한 것이다.
Exception
Exception은 OS의 Kernel에 Control을 맡겨 특정 이벤트에 대한 반응을 야기시키는 것이다. OS파트에서 자세히 다루겠지만 OS는 Kernel이라는 관리자 모드가 존재한다. Exception의 예로는 I/O Request Completes, page fault, Divide by Zero 등이 있다. 예를 들어서 current라는 User Mode의 point에서 exception이 발생했을 때는 Kernel모드가 Exception 번호를 받고 Exception Handler를 통해 처리한 후, current로 돌아가거나 다음 포인트인 next로 이동하거나, abort 될 수 있다.
Exception이 발생할 때는 Kernel에게 Exception Number를 제공해준다. Kernel에는 Exception Table이 존재하며, 이 테이블에는 각 Exception에 대한 번호로 접근할 수 있으며, 각 Exception에 맞는 Exception Handler의 Pointer주소가 담겨있다. 일반적으로 0번은 read, 1번은 write, 2번은 open 이런 식으로 많은 OS에서 저장되어 있다.
Exception은 CPU가 돌아가면서 동기적인 작업들에 대해서 동기적으로 작동을 한다. 즉 Instruction을 수행하면서 발생하는 예외상황이라는 것이다. 이러한 Exception의 동작 결과는 제 가지로 나눌 수 있다.
- Trap (Intentional Exception) : 의도적으로 Exception을 발생시키는 것이다. System Call, Breakpoint Trap 등이 여기에 해당하는데, 특히 System Call은 의도적으로 Kernel Mode로 진입하는 것이다. Trap을 수행하게 되면 PC의 다음 Instruction을 수행하게 된다.
- Faults (Unintentional Exception and Recoverable) : 의도적이지 않게 Exception이 발생했지만 복구 가능한 Exception을 의미한다. 대표적으로 Page Fault가 있는데, 이는 복구가 가능한 영역이다. Fault는 실행 후에 해당 Instruction을 Re-Execute 하거나 abort 시켜버린다.
- Aborts (Unintentioal Exception and Unrecoverable) : Fault와는 반대로 복구할 수 없는 Exception을 의미한다. 이러한 경우는 대부분 Illegal Instruction(Opcode), Parity Error 등이 있는데, 이렇게 되면 수행하고 있는 Program이 종료가 돼버린다.
Page Fault
Page Fault가 일어나는 이유를 간단히 설명하자면 User가 Memory에 Data를 Write 하려고 할 때 그 메모리 영역이 disk에 있어서 할당이 안 되는 경우이다.
int arr[10000];
int main() {
arr[5100] = 99;
}위와 같은 경우에는 bss 영역이기 때문에 앞서서 차례대로 배열에 데이터를 집어넣으면 메모리를 순차적으로 읽으면서 할당이 되겠지만 뜬금없이 저렇게 넣어버리면 아직 준비가 안되기 때문에 할당이 코드가 제대로 한 번에 돌아가지 않을 수 있다. 이러한 Fault 같은 경우에는 단순하게 current instruction을 재실행하면 문제가 되지 않는다. User영역에서 저 데이터를 넣기 위해 movl 하는 코드로 Instruction이 만들어진다면 Kernel은 해당 page를 disk로부터 Memory로 가져와서 다시 실행하면 된다는 의미이다.
Invalid Memory Reference
흔히 Segmentation Fault라고 불리는 상황이다. 잘못된 메모리를 읽었을 때 발생하며, 이 경우에는 Instruction이 재실행되는 것이 아니라 Abort 된다. 당연하게 생각을 해보면 해당 Instruction을 재실행했을 때 똑같이 잘못된 메모리 주소를 참조해야 하기 때문에 Process를 Kill 해버리는 것이 맞다. Flow를 간단히 설명하자면 Page Fault Exception이 발생하고, Invalid 한 Memory를 참조하고 있다면 해당 Process를 Terminate 시킨다.
Interrupts
Exception과 비슷하지만 Interrupt라는 개념 또한 존재한다. Interrupt는 Processor 내부에서 발생하는 Event들이 아니라 CPU 외부에서 Event들이 발생해 이를 처리해야 하는 것을 의미한다. 즉, Event신호가 외부에서 오기 때문에 CPU에 대해 비동기적 신호라고 할 수 있는 것이다. Interrupt를 처리하는 방법은 Processor의 Interrupt Pin을 setting 하고, Interrupt Handler을 수행한다. 그리고 Handler는 다음 수행할 instruction을 return 한다. Interrupt의 예시들은 대표적으로 Timer Interrupt와 I/O Request들이 있는데, Timer Interrupt의 경우 CPU는 몇 ms마다 Interrupt를 발생시킨다. I/O Interrupt는 우리가 일반적으로 Ctrl + C 하거나 Disk로부터 데이터를 읽어야 할 때 발생이 된다.
| Interrupt | Exception |
| External to CPU | Internal to CPU |
| Asynchronous to Clock | Synchoronous to Clock |
| Current Instructions must be Completed | Current Instruction may not completed |
이렇게 Interrupt와 Exception을 간단하게 정리해볼 수 있다. 이에 대한 자세한 내용은 OS Part에서 다뤄보자.
System Call
앞서서 Trap이라는 것을 살표본 적이 있다. Trap은 의도적으로 Exception을 발생시키는 것인데 이와 System Call은 거의 유사라다고 볼 수 있다. 책에서 System Call에 대한 정의는 아래와 같다.
The most important use of traps is to provide a procedure-like interface between user programs and the kernel, known as a system call.
번역하자면, Trap을 사용하는 목적은 Programmer Level에서 OS의 서비스, 즉 커널 모드의 영역의 서비스를 사용자가 접근할 수 있는 인터페이스의 개념이라는 것이다. 다시 말해서 User가 만든 Application(Program)이 OS와 통신하기 위한 방식이라는 것이다. 운영체제 쪽에서 자세히 다루겠지만, OS는 컴퓨터의 자원을 관리하는 역할을 수행한다. OS는 자원을 보호하고, 효율적으로 사용할 수 있도록 만든다. System Call의 목적도 이와 같다. System Call로 하여금 User의 Program이 OS의 자원에 직접적인 접근을 막고, 대신에 System Call을 활용함으로써 OS의 관리 하에 HW적인 자원을 User가 사용할 수 있게 해주는 것이다. OS의 입장에서는 OS Level의 자원들만 신뢰할 수 있다. 자원 관리자로서 어떠한 에러나 외부 신호를 block 하고 신뢰할 수 있는 것들만 사용해야 한다. 이때 User Program은 OS의 입장에서 Untrusted 된 것이다. 예를 들어서 현실적으로 User가 만든 Program은 buggy 할 수 있다. Resource를 사용해야 하는데 Infinite Loop이나, Memory Exhaust가 발생하게 되는 것은 bug이다. 또한 User Program은 Malicious 할 수 있다. User가 read/write를 한다고 할 때 잘못 HW 쪽 코드를 건드리게 되면 OS입장에서는 참 난감할 것이다.
따라서 실질적인 operation을 System Call로 수행하는 것이다. 예를 들어보면, printf라는 함수는 출력 모니터에 write 해주는 함수이다. printf는 write를 수행할 수 있는 System Call에 접근할 수 있는 함수인 것이다. write는 OS의 Kernel에서 출력을 하는 것이다. Linux x86-64에서는 특히 int 0x80을 통해 System Call을 호출한다. System Call은 매우 General 하게 작성이 되어있다. 이는 System Call이 어느 곳에서 나 Portable 하게 수행해야 하기 때문이다. 예를 들어 C++의 cout이나 put 같은 경우에는 사용자의 모니터에 출력을 해주는 기능이다. 이 함수들은 필연적으로 write라는 System Call의 호출이 일어나게 된다. 각 함수들에 따라서 출력을 담당하는 System Call을 다르게 설정해놓는다면 OS입장에서 이를 관리하는데 Overhead가 많아질 것이다.
System Call은 Unique 한 ID로서 관리가 된다. System Call 호출 시에 System Call의 번호를 호출하는 것이다. 예를 들어 write의 System Call은 대부분의 Linux x86-64 ISA에서 1번을 가리키는데, write(1, "Hello World!", 13) 이렇게 내부적으로 구현할 수 있다. 아래의 그림은 일부 System Call에 대한 번호 및 설명을 적어놓은 table이다.
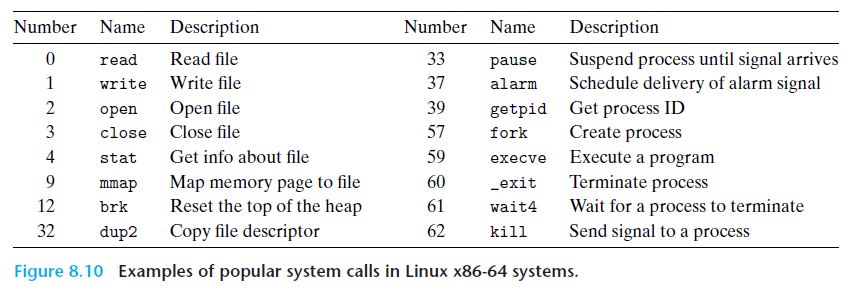
Linux x86-64에서는 %rax 레지스터에 System Call을 넣게 된다. 나머지 Arguments들은 앞서서 설명했듯이 %rdi, %rsi, %rdx, %r8, %r9, %r10으로 넣을 수 있다. 이때 System Call을 수행하고 나서 돌아오는 return value는 다시 %rax에 넣어진다. 레지스터는 한정된 자원이지만 그 속도는 매우 빠른데 이러한 자원을 전달하는 데에만 사용하면 아깝지 않은가? 그러한 의미에서 %rax에서 사용되는 것 같다. 아래의 그림들은 Linux에서 어떻게 System Call이 일어나는지 보여준다.


Exception & Procedure Call
사실 여기까지 오면서 너무나 많은 용어들이 설명이 되었기 때문에 한번 정리를 하고 넘어가 보자 한다. 여기서 Exception이란 interrupt, exception, sys call 등을 모두 합쳐놓은 용어라고 생각하면 되겠다.
우선 Exception Handler은 Kernel Mode에서 수행이 되는 것이다. 반면 Procedure Call을 쉽게 말해 함수 호출이라고 했을 때, 이는 당연히 User Mode에서 돌아가게 된다.
또한 Exception이 수행될 때의 작업들은 Kernel Stack이라는 곳에서 데이터를 저장하게 된다. 다시 말해 Stack은 User Stack과 Kernel Stack으로 구분이 되며, 당연하게 Exception도 하나의 함수 호출이라는 개념으로 바라볼 때 User Mode의 자원을 사용하는 것이 아닌 Kernel내에서만 Trusted 된 자원을 사용해야 하기 때문에 Kernel Stack을 활용한다.
마지막으로 PC를 생각해봤을 때 일반적인 함수 호출이 일어나면 PC는 그다음 Instruction을 수행할 주소를 가리키게 된다. 반면 Exception은 current instruction으로 되돌아갈 수도, next instruction으로 갈 수도 있다.
System Call Failure
Kernel Mode에서 수행되는 System Call도 다양한 이유에 의해 실패할 수 있다. System Resource가 전부 소진될 수도 있고, argument가 invalid 할 수도 있고, permission이 없는데 수행하려고 하느라 실패할 수도 있고, 외부 Device에서 에러가 날 수도 있고 다양한 이유에 의해 System Call 호출에 실패할 수도 있다.
이러한 경우에 Linux에서는 System Level에서의 실패, 혹은 에러 상황에서는 대게 -1을 return 하게 된다. 책에는 NULL도 return 될 수 있다는데 참고만 해두자. errno 하는 variable을 전역 변수로 사용해서 이 원인을 파악할 수 있다. 정확한 실패, 에러의 원인을 확인하기 위해서는 errno.h라는 header 파일이 필요하며, System Call은 에러에 대한 정보를 담기 위해 errno 변수를 활용하게 된다.
에러 정보에 대한 자세한 명세는 Linux에서 errno -l 명령어를 통해 아래와 같이 확인할 수 있다.
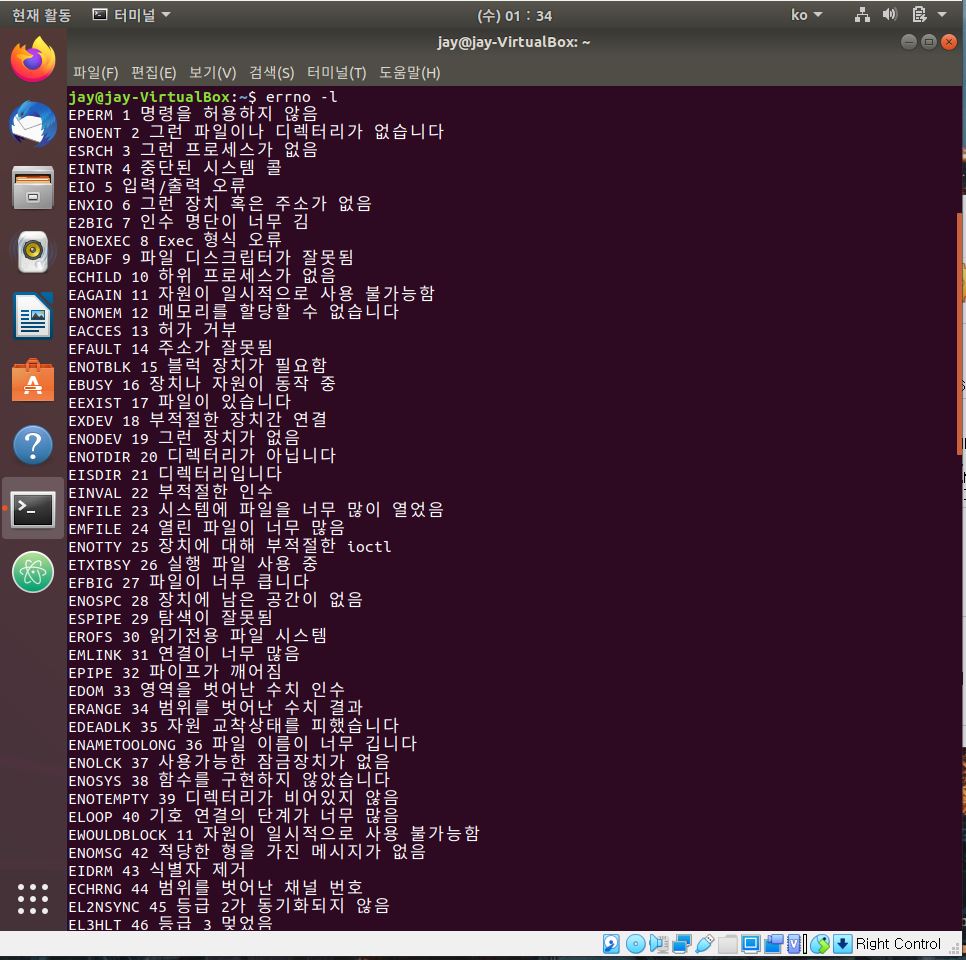
void perror(const char *s)라는 함수가 있다. 이는 errno의 value에 맞게 error의 메시지를 출력해준다.
char* strerror(int errnum)이라는 함수 역시 errnum에 따른 에러 메시지의 포인터를 return 해준다.
이 함수들도 알아두면 도움이 될 것 같다.
Exit Status
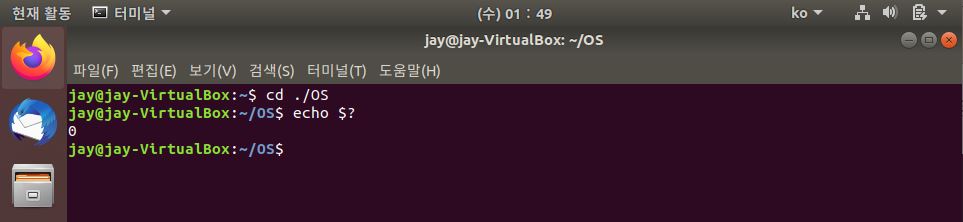
모든 UNIX/LINUX 계열의 Program들은 Process가 종료될 때마다 자신을 호출한 Process에게 integer를 return 하게 되는 게 이것이 Exit Status이다. 우리가 C나 C++를 코딩할 때 항상 main함수에서 마칠 때 return 0을 써준다. 이때 0이 시사하는 바는 Process가 정상적으로 종료했다는 것을 알려 준다. 만약 이 Exit Stauts가 0이 아닐 경우에는 성공적으로 Process를 끝마치지 못했거나 에러가 발생하는 것을 의미한다. Linux의 Shell에서는 $?를 통해 확인할 수 있다.

Wrapping Up
사실 OS를 제대로 들어가지는 않았지만 Sys Call과 관련해서는 어느 정도 OS적인 지식도 필요하기 때문에 너무나 많은 개념들이 소개가 되었다. 많은 개념들을 잘 정리하면 확실히 운영체제(OS)를 배우는데 많은 도움이 될 것이다.
Reference
Randal E. Bryant, & David R. O’Hallaron. (2016). Computer Systems A Programmer’s Perspective Third edition. Carnegie Mellon University: Pearson.



